Every organization needs an effective threat detection and response capability. It is the foundation of effective cybersecurity practice, and for most organizations, it’s a conceptual no-brainer.
However, many organizations struggle to make their threat detection and response plans a reality. There is a plethora of tools, vendors, and processes to explore, making it difficult to know where to start. Overwhelmed by the various options available, many organizations end up developing an inefficient and ultimately substandard threat detection and response capability that fails to meet their needs.
This article provides a pathway to avoid this outcome and instead build a threat detection and response capability that is efficient, effective, and scalable. Using a series of best practices backed with practical how-to guides, it shows you the core disciplines you need to get right while avoiding tool bloat and unnecessary operational complexity. Read on to learn more.
Summary of key best practices for threat detection and response
Establish effective logging
All threat detection and response begins with developing an understanding of your operational environment. Without this understanding, it is utterly impossible to detect and respond to threats. You need to establish an effective logging solution, which is far more complicated than finding a great database and piping in some logs. It relies on three key outcomes: getting the right logs, to a central location, normalized to a common data schema.
Each of these is expanded on the subsections below, in the order in which you would normally approach the problem.
Create a centralized logging location
Start by establishing a centralized logging location. Generally, this is a security information and event management (SIEM) system or security data lake with a single goal: to create a central repository where raw telemetry is normalized, enriched, and made searchable.
Doing this allows you to take multiple data streams and stitch them together. When it's done well, an investigator can take a single event from one part of your infrastructure and quickly map its connections, dependencies, and activity timelines to other events from other parts of your infrastructure. This provides context for the event and enables an investigator to define things like attack paths, blast radius, and dwell time.
Centralization also unlocks consistency in detection engineering. Instead of building point solutions that only work in one environment, detections can correlate across different sources. For example, a detection on a suspicious process execution on a server can be expanded to include things like related failed logins, DNS requests, or a cloud API call.
For most organizations, the selection and deployment of a centralized logging system is a collaborative effort between engineering and threat detection and response teams. This is normal because many centralized logging solutions have a large infrastructure footprint, requiring specific engineering expertise to make them viable.
In these scenarios, try not to get distracted by the extraneous bells and whistles modern logging solutions offer. Instead, focus on the core capabilities that will allow you to build a highly efficient and scalable threat detection and response capability: ingestion speed, normalization, search speed, and extensibility. A list of these requirements is included below, which you can use to work with your engineering teams to specify them in a manner suitable for your organization.
Collect the right logs
When asked what logs they should collect, most cybersecurity professionals will answer “all of them” by default. This is a recognition that in an era of increasingly sophisticated attacks and zero-day vulnerabilities, you never really know what logs you’ll need until you investigate an event. A seemingly pointless application log means nothing right up until it becomes the key piece of evidence that allows you to identify a previously unknown zero-day attack.
However, collecting every log from every device all the time is impractical. Log systems cannot handle that level of volume, and at some point, you reach a place of diminishing returns. The reality is that not all telemetry carries the same weight, and part of building an effective log strategy is knowing which sources deliver the highest fidelity and then prioritizing your log ingestion accordingly.
To do this, you need to assess all the logs available in your environment and then identify which ones you need to ingest and which ones you need to discard. Some of these will be obvious; for instance, endpoint process logs, authentication events, DNS queries, firewall traffic, and cloud audit trails are almost always necessary in a modern security stack. They provide rich visibility into attacker behaviors and can be mapped directly to MITRE ATT&CK techniques. In contrast, verbose system and application logs with non-security-relevant debug information are considerably less useful. Unless there is a specific organizational requirement to include them, they are best left alone.
Once you’ve culled the logs that are clearly unnecessary, start ranking the security value tiers of the remaining logs. This can be used in future negotiations with your engineering team, or, if you're taking a staged log ingestion rollout approach to your integration, as a way to prioritize what logs you need. Here’s an example of what this looks like:
Normalize all logs
Finally, once you’ve collected all your logs into one place, you need to make them consistent with each other. This is the final step in centralizing all your logs together, and it is what makes them actionable, allowing all downstream actions to leverage a common data schema. Without this process, every new data source becomes a custom one-off project, and your detections break the moment a vendor changes a field name.
To see why this is important, consider something as simple as a username field. In one log source, it might be called “user,” in another “accountName,” in another “principalId.” Some logs may capture it in uppercase, some in lowercase, and others might split it into domain and user. If you don’t normalize, your query for a single user across multiple systems will return incomplete or misleading results. Left unchecked, this can completely invalidate all the work you’ve done so far to centralize all your logs.
Leverage the built-in functionality that almost all centralized logging solutions provide as part of their offerings. In the instances where it isn’t included (such as custom logs you’ve self-developed), work with your detection engineers and engineering teams to ensure that a lambda function or equivalent is included in your log ingestion pipeline. This function will analyze each incoming log at runtime to normalize it according to your log schema.
Integrate workflow orchestration and automation
One of the core capabilities of a modern threat detection and response capability is the ability to scale operational impact faster than headcount. This is more than just a cost minimization consideration; it’s also a recognition that operations leveraging compute and analysis integration for their work are more effective and scalable than their human-resource-intensive equivalents.
The way you do this is through workflow orchestration and automation. You want to reach a stage where this is so ingrained in what you do that every aspect of your threat detection and response capability is built with this in mind.
To see why this is important, consider the common workflow below:
A SIEM system sends notification of a potentially malicious IP address.
An analyst checks the IP address in a service like GreyNoise.
If the IP address is malicious, the analyst blocks it at the relevant firewall.
The analyst updates a case management system.
This flow would take a human around five minutes. Depending on the setup, this person would be required to access at least three different screens and manually transfer information at each stage. Each time they do this, there is an opportunity for errors to occur, so it is necessary for that person to constantly remain alert and focused. Furthermore, scaling the process is reliant on scaling headcount, and each time a new person is added to the team, you must accept the training, mentoring, and employment responsibilities for that person.
In contrast, the workflow below fully automates this process and even extends it to include a Slack notification. Even better, if you’re using a platform like Tines, this workflow can scale to an arbitrarily large number of events with no input from you. Imagine a similar level of workflow orchestration and automation happening across your entire threat detection and response capability.
Analyze Elastic alerts, block IPs, and notify in Slack and Tines Cases
Analyze Elastic Security alerts for IP threats using GreyNoise and block malicious IPs with Google Firewall. Communicate the incidents on Slack and log the details in Tines Cases.
Although workflow orchestration and automation offer tremendous benefits, it is not quite as simple as connecting up a new platform and everything being magically better. Instead, there are three key processes you need to get right in order to leverage this discipline to its maximum value. These are outlined below.
Develop an effective integration process
Workflow orchestration and automation should be approached in the same way that you approach software engineering: You would never deploy a new web app feature into production without rigorous processes for how you design, develop, deploy, and assess it; you shouldn’t do it with workflow orchestration and automation either. This may seem like overkill, particularly for relatively simple automations like the one shown earlier. However, as you develop more complex workflows, you’ll quickly approach a point where a systematic approach is necessary.
Use your existing engineering frameworks, or if these are too unwieldy, you can leverage the one in the table below as a starting point. It is filled out using the example of the workflow shown earlier.
Automate playbooks
Once you have an effective integration process in place, start working on your playbooks, with the overall goal of eliminating as much repetitive work as possible. This forms the core of your workflow orchestration and automation work and is what will provide measurable decreases in human-centric work effort over time.
One quick note here: Although your overall goal is to orchestrate and automate as much as possible, you need to approach this with a crawl-walk-run mindset. No one benefits if you tackle the hardest playbook you can find and then discover you simply don’t have the skillset to deliver. Instead, start with simple workflows , then tackle more complex workflows that may also require some orchestration to make them work. Only then should you scale up your efforts.
Taking this approach helps you build credibility with your team as well as with your organization. It also ensures that you stress-test various changes you are making to your operations in a controlled manner.
Establish human-in-the-loop criteria
Every organization has a unique set of tolerances that define how comfortable they are with automated decision-making. Some organizations are comfortable maintaining control using auto-adjusting tolerance levels; other organizations require tightly scoped conditional branching logic.
What’s important is that you know what these criteria are and that they become an essential part of your workflow orchestration and automation design, planning, and implementation. If your organization has specific sensitivities about how devices are quarantined on a network, then make sure that is an essential part of your workflow orchestration when it comes to endpoint detection and response (EDR) alerts.
The easiest way to do this is to create a forum where you pose questions about specific automated decision criteria to key decision makers. This allows you to get their views and, where appropriate, provide more clarifying information.
Improve the quality of your alerting pipeline
In modern security operations, almost every single tool in your stack is constantly generating alerts, and all of these alerts are streaming into your threat detection and response capability.
The problem is that the vast majority of these alerts offer little to no value. While they can be used to form a baseline of network activity, they also form a constant stream of background noise, making it far more difficult for your analysts to find and respond to the threats you really need to care about.
As a result, if you want to build a scalable threat detection and response capability, you need to have an alert-handling strategy that focuses on three aspects: enrichment, correlation, and MITRE ATT&CK mapping.
Here’s how you go about doing this.
Enrich every alert
Start by improving the quality of your inbound alerts. This means adding more context and information to inbound alerts so that they present a more complete picture of what is going on around them. It also gives you a chance to filter out alerts that are irrelevant, duplicates, or otherwise invalid.
To see this in action, consider a theoretical threat intelligence alert for malicious C2 infrastructure that has been active for the past two weeks. Almost every threat detection and response team would act on this immediately, as it has the potential to be a critical threat to their environment.
However, in real-world operations, the first thing an investigator would want to check is the relevance of this alert to the environment. They would want to know if that IP had been observed in the environment. If so, then this alert has been validated, and further investigation is needed; if not, then the alert can be resolved.
This kind of alert qualification and enrichment seems simple, but it has profound downstream impacts on your threat detection and response operations. It is the difference between burning your team's time gathering contextual information and investing your team's time making complex, operationally relevant decisions that meaningfully decrease the risk to your environment.
For instance, here’s an example of how you can use automation to perform this kind of qualification:



Conduct IP address search using Cribl
Discover IP addresses effortlessly using Cribl. The process involves a series of steps such as forming a query, tracking search progress, and parsing results to deliver accurate IP data.
Tools
If you’ve implemented the workflow orchestration and automation discussed earlier, this same kind of process can be applied to the vast majority of your alerts. It also helps you to update your enrichment pipeline as you learn from your existing operations.
Finally, on top of general alert deduplicating and validity checking, you can add supplementary data to alerts that will help analysts and workflow platforms proceed further if needed, as shown in the table below:
Map every alert to adversary action
As a threat detection and response capability, your focus should always be on identifying and dealing with actionable threat information. This may sound self-evident, but many threat detection and response teams lose this focus and get bogged down in nice-to-have but completely unnecessary alerting, such as infrastructure and availability alerts.
The way to avoid this is to ensure that each and every alert is mapped directly to some aspect of an adversary's tactics, techniques, and procedures (TTPs). The most effective way to do this is by using the MITRE ATT&CK framework, which is a globally recognized, vendor-agnostic breakdown of all the major adversary actions and behaviors publicly released.
Integrate multi-attack-stage correlation
The final step in handling alerts at scale is integrating multi-attack-stage event correlation. This allows you to link events across multiple stages of an attack, which in turn increases the urgency with which they should be addressed. In the next section, you’ll see the practical application of how this works, whereas this section focuses on the technical capability to do so.
For instance, a laptop with a phishing email alert (initial compromise) that suddenly starts to enumerate SMB shares on the rest of your network (lateral movement), should be of far higher priority than one without the enumeration.
To do this, leverage the MITRE ATT&CK mapping from earlier, and then plug it into your workflow orchestration and automation platform. When more than one stage of adversary action is observed, make sure this is annotated in the alert.
Implement effective prioritization
Many organizations spend vast sums of money acquiring advanced threat detection and response tooling, then fail to back it up with an effective prioritization framework. Incorrectly assuming that prioritization is as simple as taking their existing risk registers, adding in a few cybersecurity risks, and performing an asset criticality analysis, they suddenly find themselves in a worse position than when they started. Now they have millions of alerts always firing and threat detection and response teams that seem to exist in a permanent state of burnout and exhaustion. Meanwhile, the organization feels no more secure than when the program of work first started.
The reality is that once you reach a certain level of technical proficiency, effective prioritization becomes the key to further progress. No matter how good your tooling is, if you don’t provide a measurable, accurate, and effective way to dynamically prioritize incoming work, you’ll never be able to get ahead of the events happening in your system.
To make this point, and to frame the rest of this section, consider the Emotet/TrickBot/Ryuk malware family. Here’s how it operated (noting that in practice, this malware had many different branches it could take depending on the environment it found itself in):
An initial phishing email was sent with a malicious attachment. This could take many forms, including XML, DOCX, PDF, and JavaScript files, with the goal of constantly evolving in order to evade detection.
Once an attachment was activated, a secondary payload was downloaded and activated. Once again, this could take several forms, including PowerShell, VBA, or a WMI provider that activated a PowerShell script (which would cause it to run with system-level privileges). Specific anti-detection and anti-defence measures were included, and some parts were executed out of memory rather than on disk. This also activated a multi-domain command and control framework that the attacker could use to interact with the malware family as it performed its attack.
Once the secondary payload was activated, it installed itself onto the operating system and achieved persistence using a scheduled task and registry key. Then it injected itself into memory in a critical system process (typically SVCHost or LSASS).
Next, it started moving through the network. Often, this was done by enumerating SMB network shares and then using previously released SMB exploits to repeat its installation on other machines.
As it started moving through the network, it would start harvesting credentials and pass these back to the C2 node, with the overall goal of finding higher-value assets.
Once enough value targets had been identified and the network well mapped, the Ryuk ransomware executable was released.
Here’s a visual of this process in action:
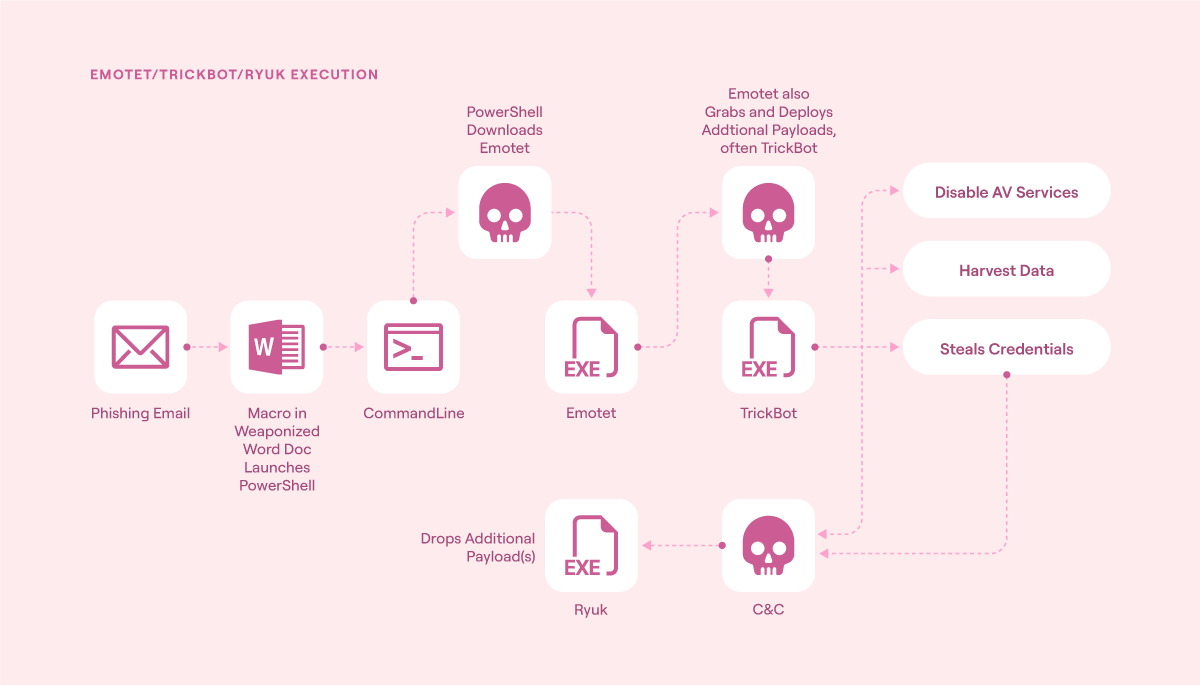
Emotet/TrickBot/Ryuk execution flow (source)
Now take this malware and apply it to your typical static prioritization framework:
Phishing emails are typically treated as routine annoyance tasks that are just a cost of doing business on the internet. Generally—and particularly when the target is a non-critical business user—they are handed to L1 analysts, with a standard response methodology of wiping the machine (if the compromise was successful) and replacing it. This process typically takes 1-2 hours to respond to, plus whatever time it takes the analyst to execute the wiping and restoration. In the case of this malware family, that timeframe is more than sufficient to elevate its privileges and move laterally further into the network.
Subsequent alerts for events like PowerShell execution and downloads on that endpoint are often ignored because, according to most playbooks, the problem has been resolved by the wiping and restoration of the system. Certainly, very few organizations would go to the effort of performing the advanced disk and memory forensics on every phishing alert that would be required to figure out what was going on.
Later alerts on other machines (post lateral movement) are treated in isolation, meaning that unless the asset criticality increases, there is no particular urgency or context associated with the alert.
Clearly, a more effective approach is needed. Organizations need a simple yet effective prioritization framework that dynamically focuses effort on the events that pose the greatest threat to their assets. Organizations also need a framework that inherently acknowledges the asymmetric nature of the cybersecurity domain. When targeted by a highly capable adversary, a low-value asset can quickly become ground zero for a crippling cyber attack.
Here’s what a good approach looks like.
Implement a base scoring model
Start by implementing a baseline event prioritization framework. This should be based on three factors: asset criticality, kill-chain severity, and event history. Importantly, these factors should be based on events that are actually observed in your infrastructure rather than those that are possible or theoretical. Doing this allows your teams to focus their efforts on the current state of your network instead of getting bogged down in unrealized probabilities or possibilities.
Combining all these factors together results in the following formula:
Priority = Asset Criticality + (Kill-Chain Severity × Event History).
Each of the three aspects is assigned a discrete value, as described in the table below.
How the scoring model works
The scoring model works by translating the “risk = likelihood × impact” calculation into quantifiable statements with a rating of 2-18. Asset criticality is used to measure impact, and the kill-chain severity and event history fields are used to calculate a likelihood value.
At the same time, the model reinforces key things that make sense to cybersecurity practitioners but can be non-obvious to others. For instance, a non-critical asset that exhibits privilege escalation and lateral movement is absolutely something that should be investigated post-haste. Conversely, any deliberately internet-connected asset (regardless of its criticality) that observes reconnaissance activity such as port scanning should not. That is just part of the open Internet.
To demonstrate this model in action, the table below shows how it would have scored the progressive alerts generated by the Emotet/Trickbot/Ryuk malware family. Note how the priority quickly escalates as each new event happens even though the initial compromise was through a low-priority phishing email.
Extend and modify as needed
Once you have your baseline scoring model in place, you can start extending and modifying it as needed. For instance, many organizations have high-fidelity threat intelligence feeds. Using the MITRE ATT&CK mapping from earlier in the article and your workflow orchestration and automation capabilities, it’s easy to elevate the scoring of any related TTPs. In turn, this elevates their priority and, almost like magic, your priority score increases.
Alternatively, if you feel that more nuance is needed in how you rank assets, then this is as simple as updating the asset criticality field with a new number. The rest of the calculation will take care of itself.
The only thing to watch out for is ensuring that no single aspect of the three presented overly dominates the calculation.
Enforce regular reviews
Security operations don’t end when an alert is closed. Instead, every incident, whether it’s a confirmed threat or just another false positive, is a data point that can sharpen your detection and response program. Only by systematically analyzing what’s happening in your environment can you create a feedback loop that strengthens detection coverage, tunes out wasted noise, and matures your processes over time.
Regular review sessions give your team the space to step back from day-to-day firefighting and identify patterns. For instance, analyzing a true positive (TP) might help your team understand why a particular alert worked while also revealing that it triggered a bit too late in the kill chain. Conversely, a false positive (FP) helps highlight blind spots in alert logic or missing enrichment data. Both are valuable because they show you where to focus engineering time, either in building earlier, higher-fidelity detections or in tuning out noise that wastes analyst hours.
While the importance of regular reviews is well known to most cybersecurity practitioners, making them work on a sustainable basis can be challenging. There are numerous demands on threat detection and response teams, and making time for something else can be challenging. Teams are already exhausted, and they need something that will take the pressure off their day-to-day operations, not just another talkfest.
A simple, repeatable process to achieve your goals while minimizing disruption is to hold biweekly review sessions. You can break this down into three areas for analysis: alerts, automation, and incident handling. In each meeting, choose one area to focus on, then invest your time solving for that focus. Finish each meeting with no more than two action items, and then work to improve them.
For alerts, gather your recent alerts, categorize them as TP or FP, and capture the lessons learned. If malware was only caught at the command-and-control (C2) stage, ask: What signals could have flagged this earlier? Was there suspicious PowerShell execution, unusual authentication, or abnormal DNS behavior that preceded it? Designing detections for those earlier behaviors means the next intrusion attempt can be stopped before it escalates.
For automation, focus on the intersection of alerting and workflow orchestration and automation, framed around reducing wasted effort. If the same false positive keeps surfacing and it's not a tuning problem, enrich it out of the pipeline using your automation. If the same mechanical process is required for every alert, create an automation to solve it. Over time, these small changes will start buying your teams back time, and they, in turn, will buy into the process.
Finally, create a narrative of continuous improvement by reviewing previous incidents. Focus on assessing areas where your processes went well or where some downfall led to inefficiency. This allows you to follow an entire threat from intrusion to eradication, providing a more expansive understanding of the event flow.
The table below summarizes these meetings in an easy-to-understand guide you can immediately implement with your team.
Last thoughts
Strong threat detection and response isn’t the result of a single tool, playbook, or one-time project. It’s the outcome of disciplined processes that are tested, tuned, and automated over time. Centralizing telemetry, integrating workflow orchestration and automation, and prioritizing alerts effectively all feed into the same goal: building an operation that learns and improves with every cycle.
The key is consistency. These aren’t box-checking exercises to be completed once and forgotten; they’re habits that compound. Each round of tuning reduces noise, and each workflow frees up analyst time. Each review session closes detection gaps earlier in the kill chain. Over time, those incremental gains turn into a measurable advantage: a security team that responds faster, investigates more accurately, and adapts more resiliently to evolving threats.
The organizations that thrive aren’t the ones with the flashiest dashboards or the biggest log pipelines. They’re the ones that invest in repeatable, data-driven processes and reinforce them with automation. That’s how you turn raw alerts into confident decisions and how you build a threat detection and response capability that transforms your security operations from reactive to truly proactive defense.