A security operations team (SecOps team) forms the frontline of organizational defense. The team is tasked with a variety of functions, including monitoring, detecting, investigating, and responding to cybersecurity threats in real time.
This article presents key best practices to help modern SecOps teams stay proactive, responsive, and resilient in high-stakes environments. Specifically, this article focuses on day-to-day operational use cases and highlights strategies for creating a successful SecOps team and processes.
Summary of best practices for security operations teams
Choose a security operations model
There is no one-size-fits-all approach to security operations. Each organization has unique needs that are shaped by various factors. Some of these factors include risk profile, industry, size, and regulatory environment.
Choosing a model that works best for your business is essential. Picking the right model is not just about resources—it’s about aligning various aspects of your organization with your security objectives and business strategies. It is also important to factor in the operational considerations that come with each model.
Dedicated model
The dedicated model involves an entirely internal team that is responsible for end-to-end SecOps. These teams are typically centralized and operate around the clock to maintain complete visibility and control over the security environment at all hours of the day.
Best suited for: Large enterprises or highly regulated industries that…
Require maximum control over SecOps
Have the budget for 24/7 staffing
Have strict compliance and data sovereignty requirements
Examples:
Financial Institutions
Defense contractors
Healthcare systems and hospitals
Hybrid model
The hybrid model blends internal enterprise with external support. For example, an organization might rely on a managed security services provider (MSSP) for Tier 1 alert triage while keeping Tier 2+ investigations and incident response in-house.
Best suited for: Organizations with moderate resources that…
Want to extend coverage without fully outsourcing
Need to scale quickly
Want to retain internal decision-making and incident ownership
Examples:
Mid-sized-to-large enterprises scaling up security maturity
Critical infrastructure operators
Tech companies expanding into regulated markets
Retail chains with distributed environments
Outsourced model
The outsourced model involves handing off some or all security operations functions to an external provider, with the scope of coverage—particularly for containment and recovery—determined by the specifics of the service-level agreement (SLA).
Best suited for: Small to mid-sized organizations that…
Have limited internal security staffing
Are looking for cost-effective 24/7 coverage
Need fast deployment
Examples:
Small and mid-sized businesses
Startups without dedicated SecOps teams
Non-profits or educational institutions
Federated model
The federated model places security analysts within individual and specialized teams, while aligning with a central security governance structure. This embeds security deeply into development and operations cycles.
Best suited for: Technology-driven companies that…
Have multiple autonomous teams, such as SaaS providers
Are pursuing DevSecOps maturity
Examples:
SaaS platform companies with multiple product lines
Multinational corporations with regionally independent teams
Conglomerates with multiple subsidiaries and brands
Virtual model
The virtual model is distributed by design and allows analysts to operate remotely, usually across locations and time zones, with minimal physical infrastructure.
Best suited for: Remote-first or global organizations that…
Are seeking maximum flexibility
Want to reduce infrastructure costs
Operate a follow-the-sun model
Examples:
Global tech companies
Remote-native startups
Consulting firms with analysts across time zones
Cloud-native businesses with minimal physical infrastructure
Model comparison
While each model offers different advantages, it’s important to understand how they compare across key operational dimensions. The table below highlights considerations for people, processes, technology, and risk mitigation across the various SecOps models.
Practical example
A mid-sized financial technology company with a small internal team adopts a hybrid model, using a third-party MSSP for 24/7 monitoring and maintaining an internal Tier 2 team to handle escalations, incident response, and tuning.
This allows them to do the following:
Keep internal control over sensitive customer data and high-impact decisions.
Avoid 24/7 staffing costs internally.
Develop custom processes and playbooks that are best suited to the company’s needs while benefiting from the MSSP’s detection coverage.
Integrate workflow orchestration and automation
Orchestrating and automating security operations workflows helps streamline security operations processes, making the organization more secure. Embedding this approach to security operations in your team planning and recruiting enables your security operations team to be more effective and efficient.
As SecOps teams mature, the ability to scale effectively becomes critical, and that scale depends heavily on minimizing manual effort and maximizing consistency. To get there, teams must understand the distinction between automation and orchestration. While the two are closely linked, they serve different purposes:
Automation handles individual, rule-based tasks without human intervention. This is ideal for repetitive actions such as IP enrichment or alert tagging.
Orchestration connects these tasks into end-to-end workflows that span tools, teams, and decision points, enabling more dynamic and adaptable response processes.
Here are some examples of orchestration workflows that chain together multiple tools and automated processes to handle complex security issues:
Building orchestration and automation into the foundation of your SecOps team rather than treating them as afterthoughts requires upfront planning and clear ownership. From playbook design to analyst training, these elements should be baked into how the team operates. The table below outlines key actions to take, when to take them, and who should be responsible.
Standardize incident response playbooks
Incident response should never rely on memory or improvisation. As SecOps teams grow in complexity, the need for structured and repeatable processes becomes critical. Standardized playbooks provide the foundation for consistent responses across analysts, shifts, and incident types. This ensures that actions are clear, defensible, and aligned with organizational policy.
Developing strong playbooks is not a one-time effort. It is an iterative process that evolves as your SecOps team handles more incidents. Most teams evolve from ad hoc or undocumented practices to fully orchestrated and optimized workflows as their capabilities evolve. This transformation follows a familiar pattern: progress may be slow at first as teams define roles and processes, but accelerates rapidly once foundational elements are in place. Over time, growth levels off as optimization and refinement take hold.
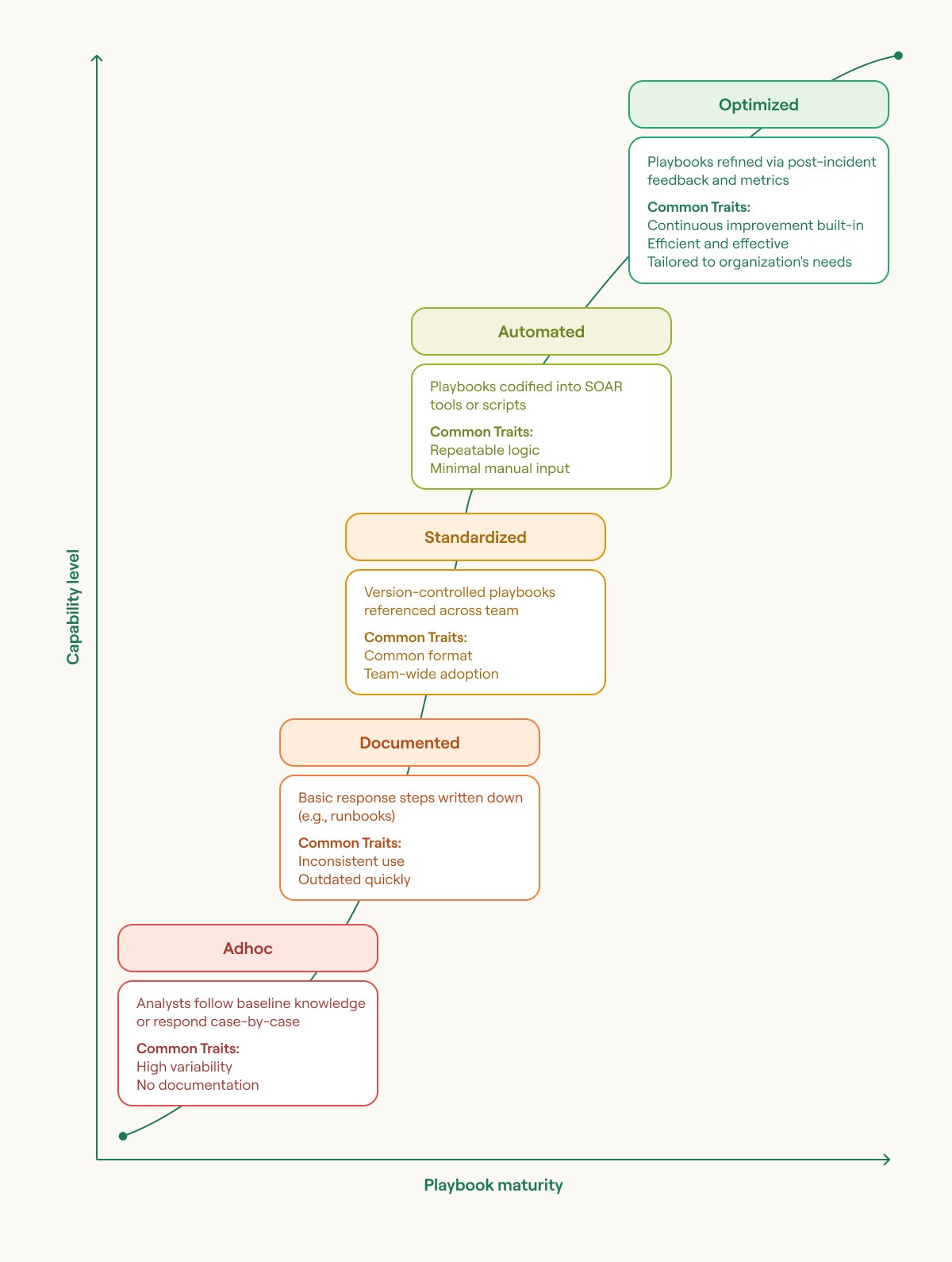
Playbook maturity stages (source)
Visualizing this curve helps teams understand where they are in their journey and what investments are needed to move forward. Recognizing the components of well-designed playbooks is the first step. The table below outlines common elements and examples of how they function in a context of real-world security operations.
Prioritize continuous tuning
As the security landscape becomes more complex, detection logic and alerting thresholds must evolve to keep pace. Without continuous tuning, teams risk being overwhelmed by false positives, missing critical alerts, or simply burning out their analysts. As such, effective detection engineering is not a “one-and-done” task—it’s a lifecycle. Alerts must be reviewed, triaged, and fed back into the system to improve accuracy and relevance over time.
Different types of detection mechanisms offer distinct opportunities for tuning. For example, signature-based detections can be adjusted to suppress known benign alerts for specific assets. Behavioral or anomaly-based systems benefit from refined baselines and more context-aware thresholds. Rule-based logic can be streamlined to reduce overlap or redundancy. Threat-intelligence-driven detections can be filtered by source confidence or operational context to prioritize what truly matters.
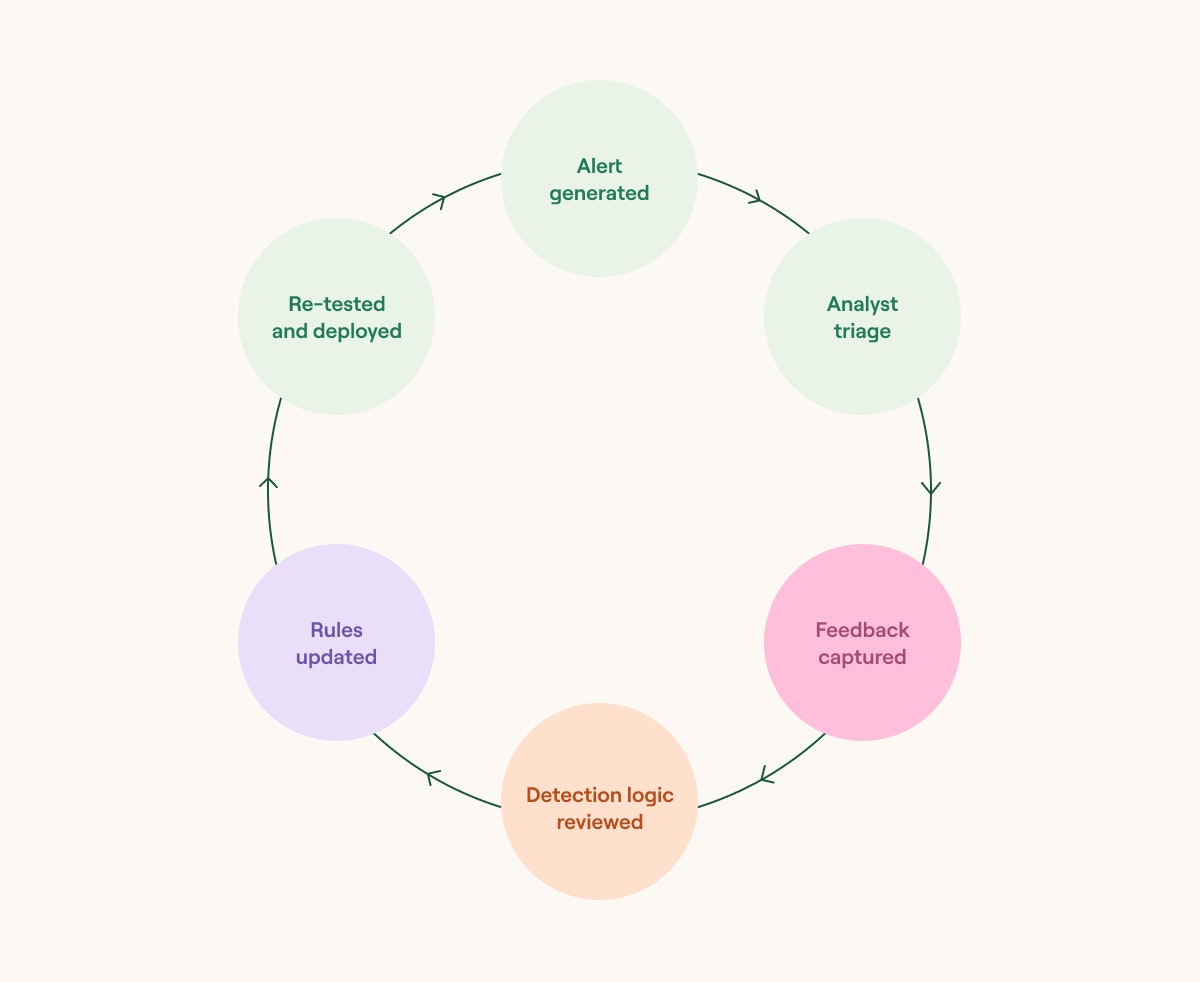
Continuous tuning cycle (source)
This continuous feedback loop ensures that detection systems remain aligned with real-world conditions and emerging threats. By treating tuning as an ongoing process, rather than a reactive fix, teams can focus analyst time on the threats that matter most.
Build for handoffs and continuity
In shift-based operations, progress can only happen when context survives the handoff, not just what happened during the shift. For SecOps teams to function effectively around the clock, they must design their workflows so that context, not just activity, is transferred. This can be achieved through clear documentation, consistent tooling, and a culture of shared situational awareness.
To avoid gaps during shift transitions, analysts should use the same tools and log everything in standardized systems. Fragmentation—whether across tools, shifts, or regions—leads to duplicate effort and missed context. Documentation should live within your incident response platform, not in transient side channels like Slack or email. And teams should assume that every process is asynchronous by design since the next analyst might be in another time zone or unavailable for clarification, so each note must stand on its own.
Example: Night-shift handoff
During a phishing investigation on the night shift, analyst Alice discovers that a suspicious email was delivered to three users, with only one clicking a link. She documents all findings—email headers, sandbox results, risk decisions—within the case ticket. By the time analyst Bob picks it up on the morning shift, the complete context is there. He updates the case with new threat intel and closes it without repeating work or asking unnecessary follow-ups.
Note that effective handoffs are only a small part of the picture. SecOps teams must also design for institutional memory. This involves the ability to retain and learn from past incidents over the long term.
It is important to treat each case like a learning opportunity. That means well-documented investigations should capture both actions taken and the rationale behind those decisions. These records help create the foundation for onboarding, training, and process improvement.
Example: New hire
Six months after a ransomware incident, a new hire joins the team. While reviewing high-severity case studies, one incident stands out for its clarity: logs, decision points, containment actions, and retrospective notes are all captured in one place. The new analyst learns how the team identifies gaps, responds under pressure, and tunes detections, all without needing a direct handoff or explanation from the original responders.
By designing systems that support both smooth handoffs and lasting documentation, SecOps teams make it easier to learn from the past. In turn, this can be used to bring new analysts up to speed faster and prevent important knowledge from slipping through the cracks.
Final thoughts
Security operations teams are only as effective as the structure and practices that support them. Building a high-efficiency SecOps team requires much more than just technical skill—it demands operational clarity, repeatable processes, and standard architecture that enables the team's efforts to scale with the organization. Whether you are forming a new team or evolving an existing one, it is important to always stick to best practices to provide a foundation for long-term performance. A well-aligned team coupled with the right model, tuned workflows, and shared playbooks can respond to any incident with greater speed, confidence, and continuity.