Building a security operations center (SOC) is not about flashy tools or vendor hype. It starts with structure, the right roles, clear processes, and a focus on reducing real business risk. Most SOCs fail because they chase flashy tech instead of building a system that can operate efficiently.
This guide lays out a practical, proven framework for building or fixing a security operations center that actually works. Whether you're starting from zero or untangling a mess, you’ll get a repeatable model grounded in real-world operations. The approach works across cloud, on-prem, and hybrid environments and scales with your growing operations.
This framework covers best practices for how to define strategies around your tactical threat model, operationalize playbooks, and layer in automation where it matters, focusing on the foundational architecture of an effective SOC without diving deep into specific tools and technologies.
Key security operations center best practices
Choose a SOC Model
Before you buy tools or hire analysts, pick your model. The structure of your security operations center sets the tone for everything else, including staffing, capabilities, response, and long-term maturity.
Although there are many different ones to choose from, they can be boiled down to three core models: in-house, hybrid, and fully outsourced via a managed security services provider (MSSP), an organization that offers security services. Each has trade-offs, and choosing a model is more of a business decision based on the business's risk appetite.
In-house
Fully in-house SOCs offer full control—you can build deep relationships in the business, mature your processes, and engineer everything to your threat model. But it’s not easy. You’ll need some level of coverage (possibly 24/7) from day one, either through human staffing or heavy automation. That level of automation takes years to develop, and likely, you will have to man a 24/7 team in the beginning.
Hiring experienced engineers is expensive, and retaining them is a challenge. Still, for companies whose business depends on data integrity or product availability—think SaaS, fintech, and defense—this is often the ideal model that makes sense.
Hybrid
Hybrid SOCs are a strong choice for companies early in their journey. You keep high-leverage tasks—like detection engineering and T3 Incident response—in-house. Meanwhile, you outsource aspects of your SOC capability, such as 24/7 alert monitoring, to an MSSP. This gets you continuous coverage without burning out your team, while buying you time to invest in automation. Over time, as you reduce alert volume and improve internal capability, you can phase out the MSSP and move toward full ownership.
MSSP
MSSPs offer low overhead and quick setup. You get around-the-clock monitoring, escalation, and coverage without internal staffing. However, that comes at the cost of visibility, speed, and customization. If your primary goal is to meet a compliance requirement and you don’t face high-value threats, an MSSP might be enough; just know that it won’t get you to a mature security program on its own.
Model comparison
At the end of the day, this is a business decision. If you're just looking to check the compliance boxes, go with an MSSP. But if you want to build a real security program that drives value and isn't just a cost center, you need in-house expertise, or at least a hybrid model.
For most organizations, the most pragmatic path is to start hybrid. They build a lean internal team that understands the environment and business, and then augment with an MSSP for coverage and scale. As they mature, they regularly reassess whether it makes sense to bring everything in-house or stick with the hybrid setup.
Some teams reach a level of maturity where automation does the heavy lifting; they don’t need round-the-clock staffing anymore. Instead of burning out on late-night shifts, their engineers work normal hours and then go home to spend time with their families.
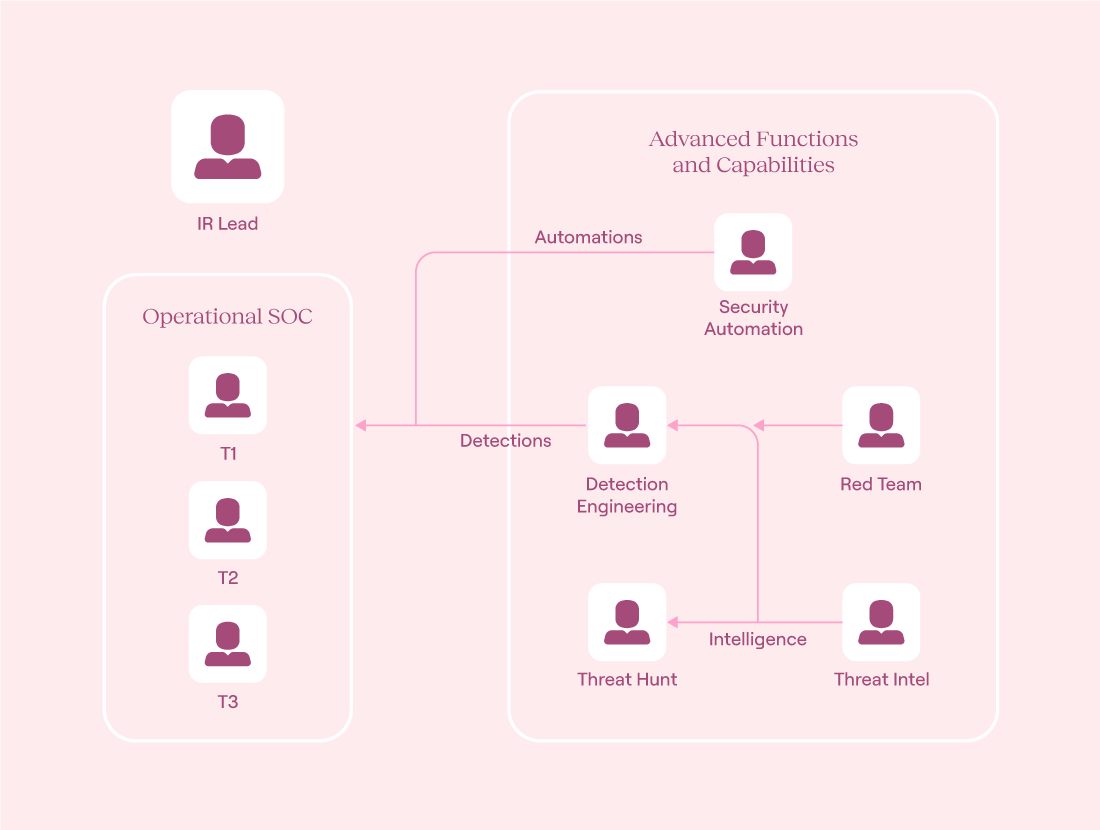
Define SOC roles and responsibilities
The roles outlined below make up a fully mature SOC. Although many organizations may never fully reach this stage, this table provides you with insight into the various roles and responsibilities you’ll need.
The foundation is always the operational tiers: alert triage, investigation, and response. Regardless of what model you choose, you will always need to cover these tiers.
Operational tiers
Start with the core operational tiers, as shown in the table below.
Early security organizations should focus on building these capabilities first, whether it is through your MSSP or in-house. That’s your foundation. Over time, individuals will naturally gravitate toward more specialized roles based on their strengths and interests. One analyst might start writing detection rules. Another might take the point on incident coordination. As the program grows, those early interests evolve into dedicated functions, and you’ll mature into a team that can cover every critical angle of security operations.
Specific roles
Beyond the operational tiers, mature SOCs rely on specialized functions to expand capabilities and coverage:
The incident response lead is the “general.” When critical incidents hit, this person coordinates across teams, communicates status to stakeholders, and drives the incident lifecycle from initial access to lessons learned.
Detection engineers build and tune the detection logic for visibility gaps or other business use cases. These individuals write rules, validate coverage, and keep alert quality high; they're the bridge between threat intelligence and the analysts.
Threat intelligence analysts track adversary behavior and deliver actionable context to detections and investigations. Their feeds enrich alerts and inform hunt missions and detection gaps.
Threat hunters proactively search for undetected threats using hypotheses and real-world TTPs. They operate outside the alert stream and push the SOC to be more proactive; instead of waiting for an alert, they hunt for indicators of compromise.
Security automation engineers build the tooling that glues everything together. From enrichment to response, these engineers automate workflows and integrate systems to cut down analyst fatigue and reduce MTTR.
Security architects set the blueprint, defining security requirements at the system design level. They make sure the SOC has the right telemetry, aligns with business risk, and can scale as the environment evolves. Good architects turn SOC feedback into infrastructure improvements.
At the “bleeding edge” of SOC maturity, you’ll see even more specialized capabilities:
Reverse engineers and malware analysts dissect payloads and binaries to extract IOCs, uncover obfuscation techniques, and generate custom detections.
Penetration testers simulate attacks to validate controls, expose blind spots, and inform both detection and response capabilities.
Security researchers stay ahead of the curve by tracking novel exploits, building proofs-of-concept, and contributing to detection engineering.
These don’t need to be dedicated roles from day one. In early-stage or smaller SOCs, a few strong operators often wear multiple hats, triaging alerts in the morning, writing detection rules in the afternoon, and jumping into IR when something breaks. That’s normal.
However, even in large, mature SOCs, these roles aren’t silos. The best teams create constant feedback loops across different functions. For example, a red team exercise or pen test might uncover blind spots in logging or alert coverage; those gaps should flow straight to detection engineering. Threat intelligence teams shouldn’t just publish reports; they should shape hunting hypotheses and validate detection logic. Automation engineers should be testing their playbooks with incident responders and tuning workflows based on real-world feedback, not assumptions.
This cross-functional interaction isn’t a nice-to-have. It’s what makes the difference between a team that just reacts and one that gets stronger with every incident.
Threat model your environment
Security operations that aren’t correlated with business context are doomed to waste time and lose funding. Your SOC can’t treat every alert equally; what matters depends on what the business does, what you protect, and who’s trying to break in. Threat modeling isn’t just a theoretical assumption but rather how you define the tactical mission of your SOC. It shapes what telemetry you ingest, what detections you write, and how you prioritize your response efforts.
Example threats by industry
The threats you face vary depending on your industry and infrastructure, so your approach needs to as well. Here are some examples:
SaaS companies: These organizations usually have a larger attack surface and leverage cloud infrastructure. Common threats include identity abuse, cloud misconfigurations, and software supply chain attacks. In this environment, your SOC should prioritize telemetry from cloud control planes, AWS CloudTrail, Azure Activity Logs, GuardDuty, Defender for Cloud, etc. You’ll want to detect unauthorized IAM activity, anomalous authentication patterns, or pipeline tampering. The SOC might also partner with cloud infrastructure teams on CSPM efforts or review infrastructure-as-code templates to close configuration gaps proactively before they’re deployed (InfraSecOps).
Defense contractors: The threat landscape here is different because insider risk and nation-state actors are the main concern. These aren’t script kiddies triggering obvious alerts; they live off the land, abuse trusted binaries, and exploit zero-days. That means your SOC needs to focus on detecting living off the land binary (LOLBIN) techniques, not just generic malware signatures. Your threat model should include air-gapped exfiltration and insider-driven data theft. Detection engineers need to watch for abnormal access patterns, like USB transfers or file access by users with no business in the project. Threat intel should also continuously drive detection engineering efforts based on evolving APT TTPs, not just static IOCs.
Ecommerce: Fraud, account takeover, and payment abuse are the top concerns here. Your SOC should monitor audit logs from customer databases and payment systems. You’ll need to build detections around abnormal user behavior, privilege changes, and indicators of fraud. Threat-hunting efforts should focus on customer account takeovers and potential abuse of customer data.
Using a structured threat modeling framework
You don’t need to invent this from scratch. Here’s a simple, high-level, effective framework for building a threat model:
Identify what matters: Document business objectives, core applications, data flows, attack surface, trust boundaries, network architecture, and high-value assets (“crown jewels”).
Map threats to those assets: Work through attack scenarios that could realistically impact those critical areas. Include both technical threats (e.g., lateral movement, service misconfigurations) and human factors (e.g., insider threat, spearphishing).
Validate with stakeholders: Bring in product, IT, cloud infrastructure, and business leads. Validate assumptions and blind spots. Make sure the model reflects real operational risks, not just theoretical ones.
Drive SOC priorities: Use this model to decide which logs matter, what alert logic to build first, what gaps to close with automation, and how to assign ownership across the organization.
Matching approach to business requirements
If you're a defense contractor running air-gapped networks, insider threats are probably your biggest risk. In that environment, a well-placed USB detection isn’t just noise; it’s critical. You build that detection, you monitor for usage, and you respond appropriately, because it directly maps to how you could get compromised.
But that same detection in a SaaS company with no proprietary data? It’s pretty much useless. Your threat model is cloud misconfigurations, not rogue USB sticks. All you’ll get is noise, wasted cycles, and false confidence. It is important to minimize low-quality alerts that lead to alert fatigue and low morale as well as potentially missed true positives in the future. Good SOCs know the difference; they align detections to business risk, not generic checklists.
Threat modeling isn't a one-time task but should evolve with the business. As the company releases new products, expands to new regions, or adopts new technologies, your threat model and your SOC should adapt with it.
Align to relevant standards
A well-run SOC goes beyond detecting threats to proving to the business that you're catching the right ones for the right reasons, ultimately reducing risk and providing a return on investment (ROI) for the business. That means aligning your work to something business leadership understands: standards, frameworks, and measurable outcomes. When your SOC maps directly to security frameworks like NIST CSF or ISO 27001, it becomes easier to justify headcount, budget, and tooling. More importantly, you start showing the business that the SOC is not an operational cost but a strategic asset that reduces risk, enables revenue, and supports business growth.
This ties directly into the threat modeling process. Once you’ve identified your core business functions, risk areas, and high-value assets, the next step is to map those risks to industry frameworks. This gives structure to your detection priorities, helps validate that you’re covering key controls, and ensures that SOC efforts are aligned with organizational goals, compliance, customer trust, operational resilience, or all of the above.
For example, your threat model might show account takeover as a key risk for your SaaS app. Mapping that to SOC 2 trust principles (security, confidentiality, availability) helps demonstrate to enterprise customers that your detections are real safeguards, not just paperwork.
A defense contractor dealing with insider threats and APT activity? That needs to align with CMMC maturity requirements, and that means ensuring incident response, access control, and audit logging are all tied to specific compliance objectives. A global enterprise operating across multiple regions may use ISO 27001 to implement a formal ISMS, giving the SOC a governance backbone that supports both business continuity and regulatory audits.
If you need a broad, adaptable framework to align risk, controls, and SOC goals across departments, NIST CSF offers a flexible foundation with terminology that leadership can understand.
Here’s a summary of relevant standards.
These frameworks shape real operational decisions. They help you define what telemetry to prioritize, what workflows to automate, and how to structure your response processes. If your threat model says account takeover is a top risk, and you’re aligning to SOC 2, then you know to monitor identity events, audit database access, and automate alert evidence for compliance. If you’re held to CMMC, your architecture must support detections for admin escalation and audit logging. These are both compliance checks and drivers for how your SOC functions.
Mapping to a framework also helps guide SOC maturity. By demonstrating how each aspect maps to a control, you support larger business objectives. That traceability builds credibility. It also helps you move from reactive firefighting to structured risk reduction, and from tactical detection writing to strategic alignment with the business.
Integrate orchestration and automation
Security teams don’t scale well with headcount alone. As your capabilities grow, the amount of work required also grows. At some point, your alert volume, response complexity, engineering initiatives, and tooling administration will outpace what even the best operators can handle. That’s where orchestration and automation come in. When done right, they let you scale your SOC’s efforts without burning out your team or increasing manpower.
Automation refers to executing specific tasks, like enriching an alert with VirusTotal data or quarantining a host. Orchestration, on the other hand, is about chaining those tasks together across tools, people, and processes. It’s the nervous system that connects detection, enrichment, triage, escalation, and response into one repeatable system that can operate independently of manual human interaction. But layering in automation takes more than just wiring up scripts; you need a plan.
Start small, then scale strategically
The best automation programs don’t start with overly complicated containment playbooks. They start with simple wins. Begin with low-risk, high-impact playbooks like case routing and Slack/Teams notifications. These save time and build confidence in the system.
As your processes stabilize, move up the stack. Automate endpoint isolation for high-confidence alerts where your detections are solid. For example, you know that a Mimikatz detection has a high true positive rate, so it would be a good candidate to feed into an auto-quarantine playbook. When the Mimikatz alert fires, this will automatically trigger quarantine of the infected host and alert the incident lead via Slack and email. Boom. You’re no longer burning out analysts with 24/7 eyes on glass. Your playbooks monitor the queue overnight, auto-triage what they can, and buy your team time to come in fresh and hit what matters.
Considerations for effective orchestration
Here are some things to keep in mind:
Standardize playbooks and processes: Before you automate anything, define how your team handles recurring alerts. Codify triage flows, escalation paths, and remediation steps. You can’t automate what you haven’t standardized.
Ensure integration across tools: Your SOAR platform is only as good as its integrations. Make sure your SIEM, EDR, ticketing, cloud, and other tools can talk to each other cleanly via APIs or webhooks.
Treat automation like software: Your playbooks and automations aren’t one-off scripts; they’re software. Treat them like it. Test thoroughly before pushing to production. Hold your security engineers accountable and enforce disciplined QA. Sloppy automation is just operational debt with a badge on it.
Version control and audit logging: Track every playbook version. Use a Git repository or your SOAR’s built-in versioning system to keep history, support rollbacks, and enable auditability across the development lifecycle.
Metrics and feedback loops: Measure what matters, including playbook success rates, human intervention frequency, and MTTR deltas. Feed those insights into tuning and backlog prioritization. Use data to scale intelligently.
Support for low-code and no-code interfaces: Modern orchestration platforms like Tines let Tier 1 analysts build and extend workflows without touching Python. Use prebuilt templates for enrichment, ticketing, and containment. When required, use Python to fill in gaps that are not available out of the box.
When you architect automation to augment your analysts, it becomes a force multiplier. Junior staff stop pushing tickets and start owning systems. Senior staff stop firefighting and start engineering. All of this combines to help your SOC scale.
Implement continuous improvement feedback loops
A static SOC is a dying SOC. Threats evolve, tools change, and what protected your environment a year ago may be irrelevant today. High-performing security teams build feedback loops into their workflows, monitor what works, what doesn’t, and adjust accordingly.
According to the Voice of Security 2025 report by IDC, sponsored by Tines and AWS, security teams are under pressure to deliver outcomes with limited resources. Nearly 50% of teams report spending the majority of their time on repetitive, manual tasks, while only 22% spend meaningful time on strategic initiatives like detection engineering, threat modeling, or training. This is where continuous improvement matters, shifting the balance from reactive triage to proactive growth.
Here are some key metrics worth tracking.
Use these data points to guide tactical changes and long-term strategy. Recurring incident spikes? Revisit playbooks and telemetry. Analysts drowning in false positives? Tune detection thresholds and automate initial triage enrichment. If most of your team’s time is going to manual triage, that’s your signal to invest in orchestration and training.
Putting it all together
A high-functioning SOC isn’t something you spin up in a sprint. It’s built through deliberate architecture, role clarity, and constant alignment with what actually matters: business risk. The foundation starts with the operating model, be it in-house, hybrid, or managed. That decision isn’t just about cost; it reflects your threat landscape, internal talent, and maturity level. Get that wrong, and everything on top cracks.
Once the model’s set, the structure has to work. Tier 1s triage. Tier 2s investigate. Tier 3s lead the response. But that’s just the frontline. A real SOC includes detection engineers writing logic, automation engineers reducing noise, and threat intel feeding proactive insights. Each piece reinforces the others. That’s how you build a system that improves every time it’s used.
And that system needs direction. Threat modeling points it toward the right logs, the right detections, and the right scenarios. Without it, you’re just checking compliance boxes. Automation scales the operation, start simple: case routing, Slack alerts. Then move to isolation and cross-platform response. Track your performance like a product: false positives, time to triage, repeat incidents. Retire what doesn’t work. Double down on what does. That’s how you move from a reactive SOC to a strategic function, one that earns its seat at the table because it defends what the business actually values.