The security operations center (SOC) is the enterprise's first line of cybersecurity defense. The SOC allows an organization to anticipate threats, respond quickly to incidents, and keep vigilant eyes on its vital infrastructure. As the cyber program's central nervous system, an effective SOC must make the organization resilient and minimize business disruption.
Though operational excellence in a SOC is imperative, it is not easy to achieve. Security operations are often bogged down by a flood of alarms, siloed tools, and a lack of people, all while contending with smart, aggressive, and persistent adversaries. This results in inefficiency, response variability, and an inability to detect and contain threats early on.
This article offers an overview of best practices to help SOC leaders optimize their operations through playbook design, telemetry centralization, automation, analyst development, and performance monitoring. Through real workflows and visualizations, the article will help SOC managers move from reactive activity to intelligence-driven operations.
Summary of key SOC best practice
Develop and maintain actionable playbooks
Effective alert triage in a security operations center is founded on thoroughly documented playbooks. These documented procedures guide analysts through common security events, reducing decision fatigue and providing consistent and timely action. Whether you are dealing with phishing, malware, or data exfiltration attempts, a well-written playbook standardizes procedures and allows for repeatable operations in the SOC.
Why playbooks matter
SOC analysts are constantly required to triage high volumes of alerts, all within tight time windows. Without well-documented workflows, decisions are made ad hoc, resulting in inconsistency, delay, and increased risk.
Playbooks are operational blueprints, enabling responses that are not only repeatable and measurable but also scalable and resilient. They simplify the onboarding of analysts, improve team alignment, and improve regulatory compliance. By decomposing response processes into routine, discrete steps, playbooks create a sound basis for automation.
Key elements of a SOC playbook
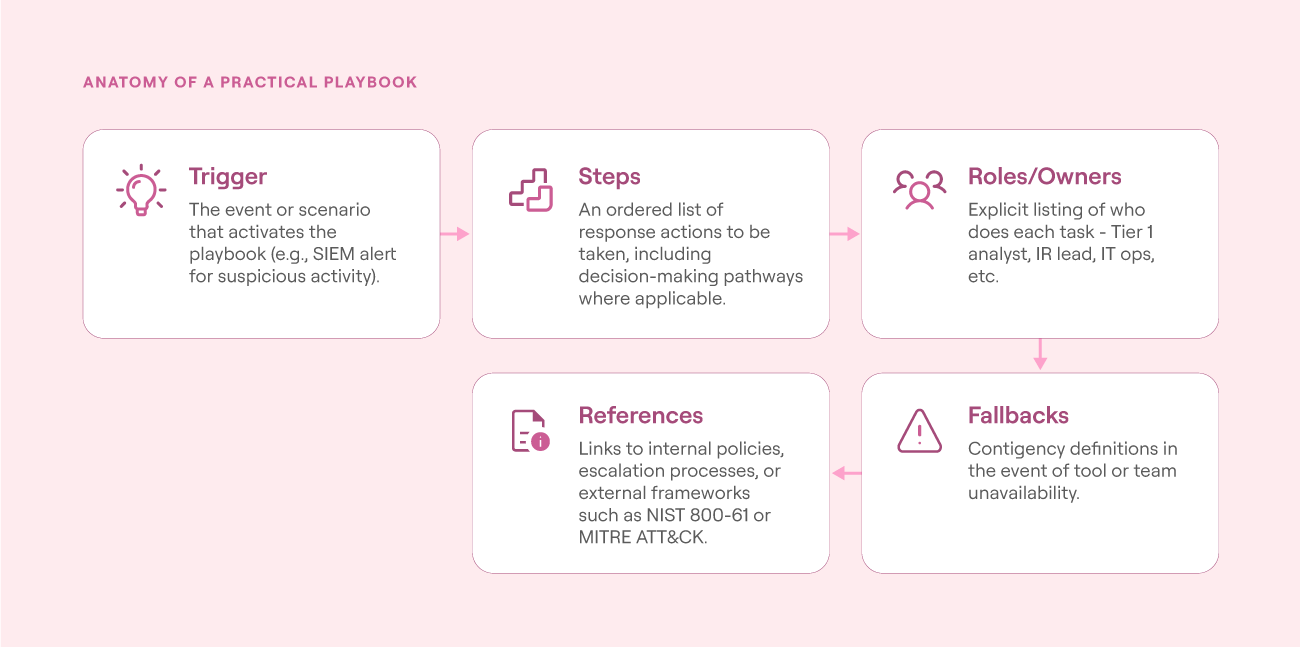
Anatomy of a practical playbook (source)
Example: Investigating and enriching suspicious Office 365 login alerts
Consider a scenario where Elastic Security provides a notification regarding a potential malicious login to Office 365. A structured playbook for handling this incident could entail the following steps:
Validate the alert: Confirm the legitimacy of the alert against peer-reviewed threat intelligence databases.
Enrich the alert: Augment the alert by gathering additional context, such as geolocation, user behavior analytics, and historical login patterns.
Notify stakeholders: Inform the appropriate teams, such as IT and compliance, of the possible incident.
Contain the threat: Where feasible, take steps to limit potential harm, such as temporarily suspending the affected account.
Document the incident: Record all the observations and measures taken for future reference and regulatory compliance.
Workflow integration
Tines allows playbooks to be automated. For the Office 365 login alert scenario, Tines has a built-in workflow that:
Receives the alert from Elastic Security
Enriches the alert with data from multiple sources
Notifies stakeholders via preferred communication channels
Monitors all activity undertaken to enable audit processes
This workflow reduces response time and upholds procedural compliance.
Framework alignment
Playbooks should align with recognized cybersecurity frameworks:
NIST SP 800-61: This standard describes a systematic incident management methodology, which is beneficial in defining phases like preparation, detection, containment, eradication, recovery, and post-incident activity.
MITRE ATT&CK: This well-known framework provides a tactical guide to identifying adversary behavior and enriching playbooks with adversary techniques.
Mapping playbooks against these frameworks enhances coverage, simplifies audits, and encourages standardization.
Integrate workflow orchestration and automation
As the number and intensity of security alerts increase, manual SOC operations become less sustainable. Workflow orchestration and automation allow security teams to scale, reduce response time, and reduce human error. Encoding routine tasks as automated processes lets SOCs increase consistency and operational effectiveness.
Orchestration vs. automation
Though closely related, orchestration and automation have different roles to play in SOC operations:
Automation refers to the operation of procedures automatically with no human interaction, such as quarantining a host, enriching an alert, or informing a stakeholder.
Orchestration coordinates multiple automated tasks and teams within a broader workflow, so activities are performed in the proper sequence and environment.
Using orchestration and automation together produces a number of benefits:
It reduces mean time to respond (MTTR) by removing manual latency.
It improves consistency by imposing repeatable behavior.
Frees up time, so analysts can focus on threat hunting and complex investigations.
Scalability Increases without the accompanying rise in personnel.
Also, automated workflows ensure that no critical steps are missed, even under circumstances involving increased alert volumes or limited resources.
Use case: Phishing email triage
Consider a typical scenario in which a user reports a suspicious email. Traditionally, this entails a series of manual processes: gathering the sample email, extracting links and attachments, executing the indicators against threat intelligence, and escalating if required.
Phishing automation workflows simplify the investigation process by breaking it into repeatable workflows. These workflows typically begin with email ingestion and proceed to parsing, enrichment, decision logic, and threat response. Each workflow removes manual labor, accelerates triage, and consists of predictable processes.
The diagram below is a typical workflow automation of a phishing attack based on a playbook-driven approach:
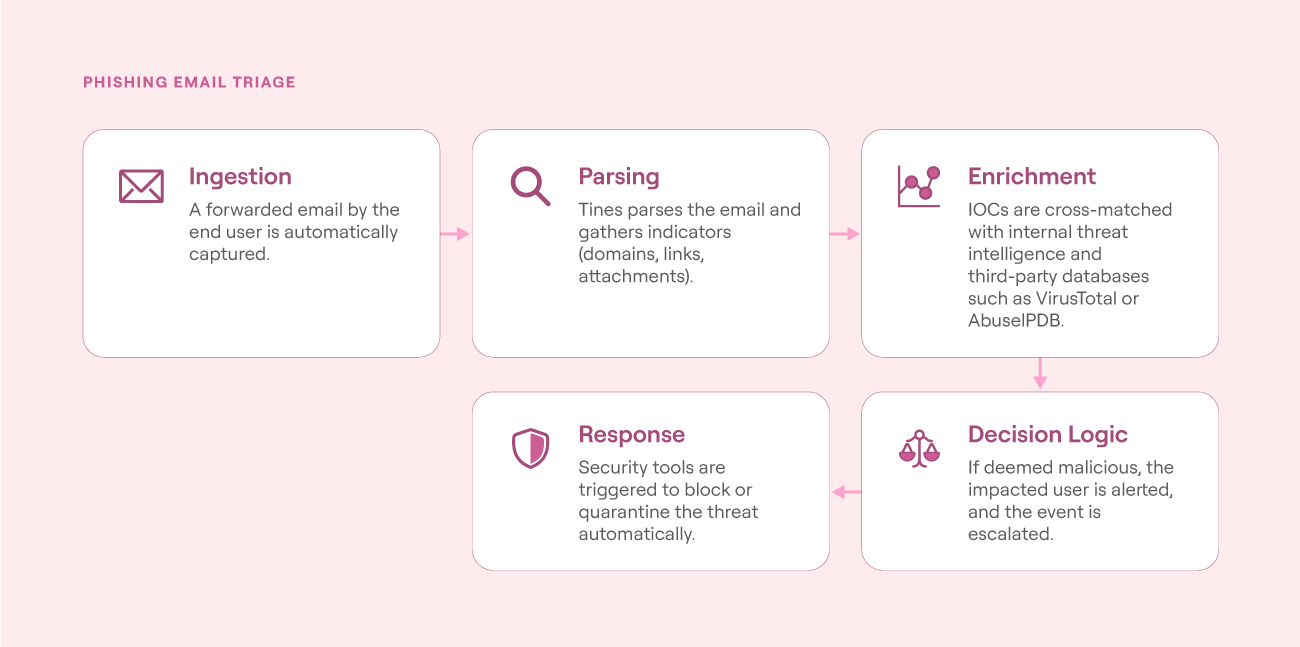
Use case Phishing email triage (source)
Workflow example
The following orchestration illustrates how a phishing alert can be automated using modular workflow components—i.e., "actions." Every action is a standalone no-code step that completes a task in the triage workflow.
Ingest email: A webhook is called with the forwarded user email, triggering the workflow.
Parse indicators: The email is scanned automatically to parse indicators like URLs, domains, and attachments.
Enrich context: To analyze likely threats, the discovered indicators are cross-referenced against internal threat intelligence and external data like VirusTotal and AbuseIPDB.
Apply decision logic: Based on the enrichment results, set criteria to determine whether the alert should be escalated or closed.
Notify and document: In the event of escalation, the relevant security team is alerted (via email, chat, or ticketing system), and the whole process is logged to enable auditability.
This orchestration—merging SIEM, email gateways, case management software, and EDR solutions—allows for a uniform, coordinated response at every point in the triage process.
Centralize visibility through SIEM and XDR
Centralized visibility is a prerequisite for any mature SOC. By correlating telemetry data from multiple information sources—endpoints, cloud, identity platforms, and network infrastructure—into a single view, analysts gain the context they need to effectively discover threats, minimize alert triage, and engage in intelligent response activities. Security information and event management (SIEM) and extended detection and response (XDR) solutions are the most common technologies employed to provide such combined visibility.
Why central visibility matters
SOCs handle information from numerous sources. Without a centralized platform, correlating behaviors across systems becomes a labor-intensive task filled with errors and inefficiencies. SIEMs manage logs and telemetry to facilitate real-time analysis, issue alerts, and conduct forensic analysis. XDR solutions elevate this by offering native integration between security controls, resulting in tighter telemetry, auto-correlation, and enhanced detection.
Central visibility enables:
Effective triaging of alerts using context-aware probes
Threat correlation across domains (from endpoint to identity to network)
Minimization of false positives by processing signals from multiple sources
Workflow automation example: Investigating EDR alerts from Carbon Black
SIEM tools can trigger alerts about suspicious behavior, including unusual logins or lateral movement. Automation workflows can be used to handle these alerts and enrich procedures when these alerts are triggered.
For instance, the workflow below ingests an alert from an EDR tool, performs an initial investigation, and then branches its action based on the investigation. Once completed, it logs all actions taken and decisions made in JIRA.


Investigate EDR alerts from Carbon Black
Get EDR alerts for applications and services that Carbon Black has started or stopped on a system. Enrich application information using VirusTotal, generate a ticket in Jira and record the details, then isolate a machine if deemed malicious.
Tools
This integration allows security teams to gather context faster and create more reliable, scalable investigation pipelines without overwhelming analysts.
Visualizing telemetry
SIEM and XDR platforms usually have built-in dashboards that visually display detection volume trends, source categories, and alert classification. Additional automation can extend these capabilities by enabling views into workflow completion rates, time-to-triage visualizations, alert classification dashboards, and SOC workload summaries. These insights help identify constraints and overloaded levels, improve detection mechanisms, and justify resource requirements to management.
Common pitfalls and how to avoid them
Although centralized telemetry has many advantages, it does have some associated challenges:
Data flooding: Without good parsing and filtering, low-fidelity logs will overwhelm analysts.
Alert misconfiguration: Incorrect correlation rules result in too many false positives.
Visibility gaps: Incomplete coverage of critical systems (e.g., cloud services) makes holistic analysis impossible.
To avoid these risks, take the following steps:
Adjust alerting thresholds using empirical evidence.
Regularly audit data sources and have full log coverage.
Employ automation to filter, enrich, and prioritize alert streams.
Invest in continuous analyst training and simulation
With threat actors constantly improving and modifying their attacks, defenders must also innovate. One way of doing this is through ongoing training, tactical simulations, and hands-on activities. These activities enable SOC analysts to develop intuition, confidence, and technical proficiency, particularly in reacting to unexpected or rapidly changing attacks.
Why analyst training is essential
SOC teams work under constant pressure, often making quick, high-stakes decisions. Without consistent exposure to changing attacker tactics, even experienced analysts can fail in real-world situations. Training initiatives not only enhance individuals' response abilities but also diminish team-wide burnout and organizational preparedness.
Well-trained analysts also:
Reduce dependence.
Decrease response delays and mistakes.
Fine-tune detection logic and actively pursue threats.
Remain motivated and active in high-stress situations.
Effective training methods
The table below summarizes some methods that are worth considering and how they work.
Benefits beyond skills
Training boosts confidence and competence, alleviating decision fatigue and reactive stress. Systematic training also facilitates certifications, upskilling, and retention. Finally, a team that trains together is more agile, decisive, and consistent under pressure.
Supplementing with playbooks and workflows
Training can be combined with automation workflows. For instance, analysts can practice responding to SIEM alerts through fake workflows, emulating real-time enrichment, triage, and escalation processes. This blended mode allows teams to rehearse not just what to do but also how to do it in the real systems they will work with during live events.
Measure performance with key SOC metrics
Metrics offer security executives insights into whether the SOC effectively identifies, investigates, and responds to threats. This facilitates the identification of bottlenecks, the justification of investments, and the continual improvement of operations. Without a data-driven feedback cycle, scaling or maturing operations becomes difficult.
What security teams are tracking
According to the IDC's Voice of Security 2025 white paper, security teams most commonly track the following:
Number of incidents handled (35%)
Mean Time to Respond (MTTR) (33%)
Percentage of recurring incidents (33.1%)
Time to detect (31.5%)
False positives identified or reduced (22%)
Mean Time to Investigate (MTTI) (26%)
Notably, while 88% of security leaders indicate that their teams are meeting or surpassing expectations, this is occurring with increasing workloads and more complicated threat landscapes. Metrics have not only become crucial in evaluating analyst effectiveness but also in proving toughness under pressure.
Metrics categories that matter
Monitoring these metrics regularly assists companies in refining detection rules, optimizing playbooks, and spending where it matters: improved tooling, additional training, or new personnel.
Automation for metrics
Automation platforms allow SOCs to streamline response workflows and monitor performance metrics. Here are some examples:
Workflow completion tracking: For instance, recording the start and end time of every step in a workflow, automatically driving MTTD, MTTI, and MTTR dashboards.
Case volume monitoring: Alerts processed by each analyst (or automation agent) can be tracked and graphed to manage workloads.
False positive tagging: Using decision logic and analyst feedback, workflows can track and store rejected or duplicate alerts for ongoing SIEM tuning.
Linking metrics to team morale and job satisfaction
The Voice of Security 2025 report also highlights a growing connection among measurement, performance, and team morale. Security leaders primarily cited “the ability to learn something new” and “creative problem-solving” as the most rewarding aspects of their jobs. However, they also cited burnout as a primary source of dissatisfaction, partly caused by high alert volume and repetitive manual tasks. Metrics such as MTTR and false positive rate not only help evaluate operations—they can also detect and remove time sinks that lead to burnout, freeing up time for more significant work.
Last thoughts
Running a successful security operations center requires more than personnel and tools—structure, discipline, and relentless tuning are all needed. From playbook standardization and visibility centralization to investing in analyst maturity and automation usage, the behaviors described in this guide are what high-performing SOCs are doing to thrive.
In an environment where threats change at the speed of light and workloads keep increasing, labor-intensive processes no longer scale. Workflow orchestration and automation platforms such as Tines aren't merely force multipliers—they're visibility, consistency, and measurable performance enablers. Combined with technically informed best practices, they enable security teams to respond precisely, learn from each incident, and consistently raise the bar. By adopting these practices, companies can transform their SOCs into proactive, intelligence-based operations that meet today's cybersecurity demands.