Network detection and response (NDR) systems are critical components of modern security architectures that detect malicious activity that evades endpoint controls and traditional perimeter defenses. These recommendations are relevant to various use cases, including lateral movement, threat hunting, and post-compromise visibility.
This article outlines a set of best practices for technical teams responsible for designing, tuning, and maintaining NDR solutions with the goal of helping align NDR operations with broader security workflows. Note that the focus is on NDR workflows; this article does not cover sensor deployment strategies or protocol-specific tuning.
Summary of best practices for network detection and response solutions
Integrate orchestration and automation
In modern NDR, automation and orchestration serve distinct but interdependent roles. Automation executes discrete tasks with consistency and speed. Orchestration, on the other hand, provides a way to link these automated actions into comprehensive workflows.
This distinction becomes particularly important as network environments grow. As the number of monitored endpoints, sessions, and alerts increases, response effectiveness relies on more than just speed—it also depends on coordinating actions in a structured and intelligent way. Orchestration enables NDR systems to operate as part of a larger detection and response fabric to include the integration of tools like endpoint detection and response (EDR) platforms, SIEMs, ticketing systems, and firewalls.
Example: Orchestrated response to beaconing detection
A company’s NDR platform detects traffic consistent with command-and-control beaconing while all of its analysts are off-shift. Rather than wait for manual review, the system initiates the following orchestrated response automatically:
Suspicious behavior is detected: The NDR system flags a session exhibiting beaconing patterns to an external IP.
Initial enrichment is triggered: The session is tagged and internal asset data is checked for context.
Threat intelligence lookup: Orchestration queries external threat intel sources for matching IOCs.
Automated decision: The asset is determined to be critical and the confidence score exceeds the response threshold.
Containment and escalation: The orchestration engine automatically isolates the host using EDR and opens a ticket on the incident.
Orchestration is extremely useful here because no analyst intervention is required, but the entire process is logged and auditable for review or tuning later.
Here is an example of an orchestrated workflow that can assist with isolating an endpoint:


Isolate a host protected by Elastic Endpoint
Use a send-to-story and a hostname to manage an endpoints isolation status in Elastic Kibana. If no device exists with that hostname, an error is returned.
Tools
Correlate signals across multiple layers
No single data source can provide a full picture. Effective NDR depends on stitching together data across various domains to build context around incidents and anomalies. Network telemetry might reveal where traffic is going, but it probably won’t know what the host was doing, or whether the destination is malicious. This leaves single pieces of information open to guessing and individuals’ interpretations.
Correlating multiple layers, such as host, network, and threat intelligence, adds clarity. Network data highlights patterns. Endpoint logs show execution behavior. Threat intelligence confirms known bad indicators. Bringing them together helps to reduce noise, increase confidence, and enable more decisive responses.
Example: Layered signal detection
An NDR platform detects a sudden spike in outbound DNS requests from a workstation. Upon investigation, the information below is gathered:
Network Layer: Traffic patterns show repeated queries to a suspicious external domain.
Endpoint Logs: At the same time, EDR flags a PowerShell script running with encoded parameters.
Threat Intelligence: The queried domain matches an entry on a threat feed tied to active C2 infrastructure.
Enrichment and Correlation: Asset context reveals that the machine belongs to a privileged administrator.
As a result, the NDR system takes the following actions:
It raises the alert priority.
It triggers host isolation workflows.
It creates an incident ticket.
Note: Check out this example of an end-to-end workflow that follows a similar pattern.

Standardize and enrich EDR alerts across platforms
Aggregate alerts from multiple EDR platforms such as CrowdStrike and Carbon Black. Enrich application details using VirusTotal, generate a Jira ticket recording the information, then isolate compromised machines.
Tools
Prioritize east-west traffic
Effective NDR is not just about protecting the perimeter. While monitoring north-south traffic (inbound and outbound) remains essential for detecting initial access and data exfiltration, it’s not enough on its own. Once inside, attackers rely on lateral movement to conduct their attacks. This can occur in the form of privilege escalation, sensitive asset discovery, or continuous persistence. Regardless of their technique, their activity often goes unnoticed without deep visibility into internal, or east-west, traffic.
NDR tools should monitor traffic between internal systems, especially between workstations, identity services (like Active Directory), and high-value servers. This means placing sensors inside LANs/VLANs and not just at the edge of the network. This allows for the inspection of traffic flows that wouldn’t typically cross a firewall. By baselining normal internal communication, it becomes easier to detect deviations that may indicate compromise.
One major challenge is that most of today’s east-west traffic is encrypted by using SMBv3, RDP, LDAP over TLS, etc. While encryption protects legitimate traffic, it also creates blind spots for traditional detection tools. To maintain visibility, NDR platforms can rely on a variety of other data, including metadata, flow patterns, behavioral anomalies, and selective decryption whenever possible. However, techniques such as JA3 fingerprinting, session timing analysis, and TLS handshake profiling can still yield actionable insights even without complete payload inspection.
Example: Lateral movement in action
An attacker launches a phishing campaign from outside the network and successfully compromises a user workstation inside a company’s internal network boundary.
Here’s the typical sequence of events:
Initial compromise: The user workstation receives a malicious payload via a phishing email. The user executes it, establishing a foothold. This endpoint becomes the initially compromised host.
Lateral movement begins: The attacker probes the internal network from this workstation using SMB and RDP to identify reachable systems and shared resources.
Internal resources are targeted: The attacker moves laterally to a nearby file server using stolen credentials, taking advantage of open internal access that perimeter defenses don’t monitor.
Privilege escalation: The attacker reaches the domain controller via unusual LDAP queries, attempting to escalate privileges or create persistence.
NDR visibility response: If the NDR system is not set up to monitor east-west traffic, the attacker remains unnoticed and can continue their malicious actions. If it is set up to monitor east-west traffic, the system can recognize abnormal peer-to-peer patterns and trigger an alert before critical systems are further compromised.
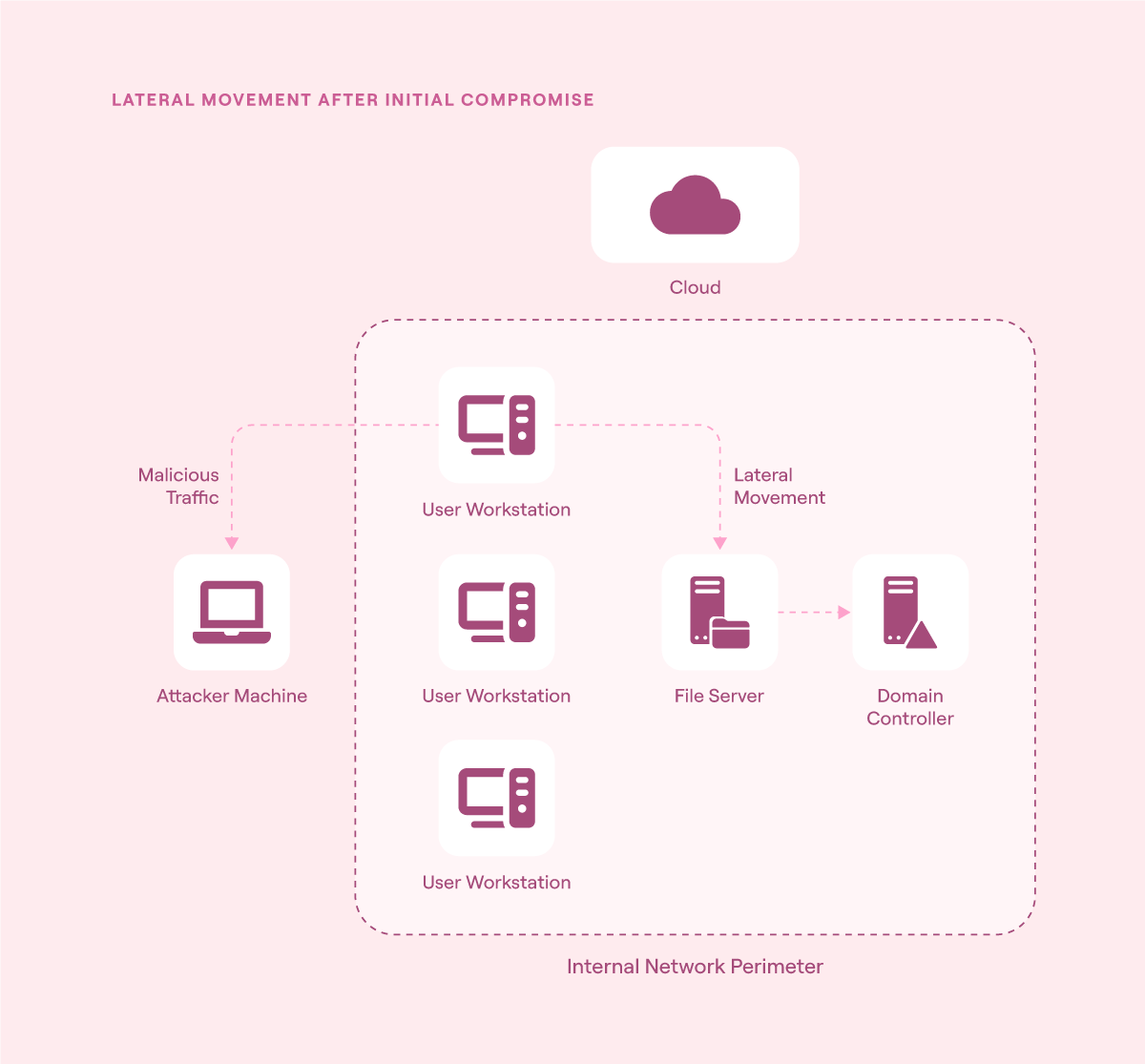
Lateral movement through an internal network after initial compromise (source)
Minimize false positives through tuning
NDR platforms are powerful, but their out-of-the-box rules are built to be broadly applicable, not tailored to specific environments. That is what makes tuning essential. Without it, even good detections can overwhelm analysts and get lost in a sea of noise. False positives are one of the fastest ways to cause alert fatigue and miss real threats.
Tuning improves signal fidelity by aligning detection logic with what’s actually normal in a network. This includes suppressing known benign behaviors (like regular backup traffic), adjusting thresholds based on asset type or frequency, and refining rules to catch relevant anomalies. It also enables contextual scoring, which gives NDR systems the ability to weigh alerts based on both risk and detection confidence. This allows analysts to prioritize threats and address the ones that pose the greatest threat first.
Feedback loops between the SOC and security engineers should drive continuous improvements to sharpen detection precision. This helps maintain analyst confidence and catch the things that really matter.
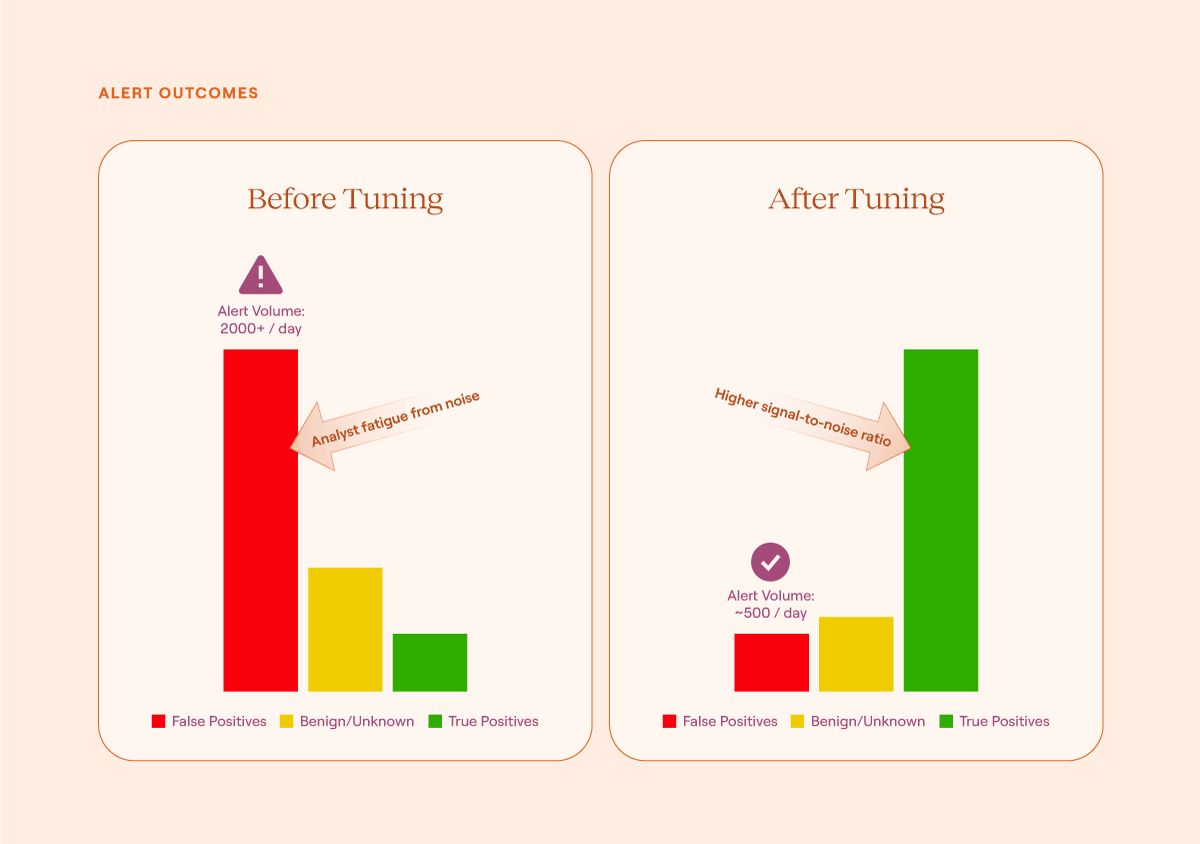
Example alert outcomes before and after tuning (source)
The signal-to-noise ratio of an NDR system can continually be improved through tuning. In the early phase of deployment, the NDR system generates excessive alerts, but over time, the SOC team tunes the system by doing the following:
Suppressing backup and patch traffic
Adjusting thresholds for known remote access tools
Refining rules for internal scanning and user behavior
Prioritizing alerts by risk and confidence
Before tuning, teams often must deal with a high volume of false positives, a large number of benign unknowns, overwhelmed and tired analysts, and difficulty in identifying real threats, which get buried. Tuning results in the following benefits:
False positives drop significantly.
True positives increase as noise decreases.
Alert quality improves and triage becomes manageable.
Analysts regain confidence in alerts.
The results include a higher signal-to-noise ratio, reduced fatigue, and faster response to actual threats.
Log thoroughly, but retain intelligently
Comprehensive logging is the foundation of strong incident management, but retaining everything indefinitely doesn't scale. Logging without a plan undermines the value of logging itself.
Without deliberate retention, logging can quickly become inefficient. It leads to bloated storage, slower performance, and higher costs, often without any real gain in security outcomes. What matters is not just collecting the data but retaining it in a way that reflects its value.
Retention policies should be purpose-driven. Certain assets, such as critical systems, regulated environments, and other high-value logs (i.e., authentication attempts, config changes, traffic summaries), deserve longer retention, while more routine or low-signal data (i.e., successful health checks, background DNS logs, scheduled job messages) can be offloaded or compressed over time. Use a mix of hot, warm, and cold storage to balance how to retain these logs.
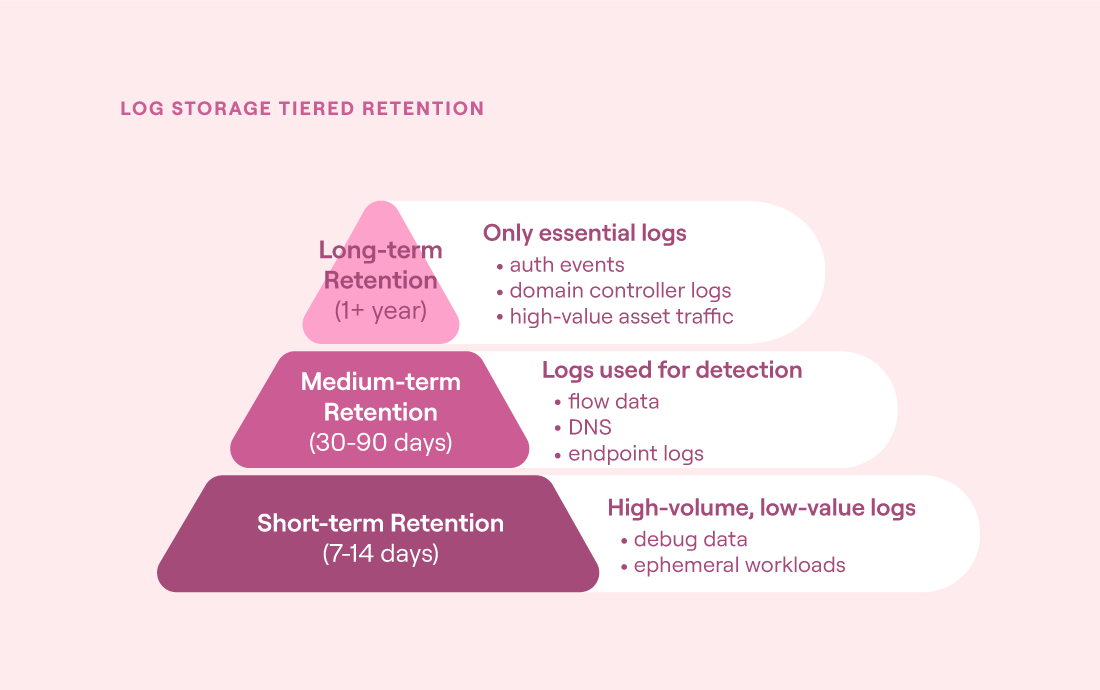
Tiered retention for log storage (source)
The following table summarizes a tiered strategy for log retention.
Use the tools at your disposal to make retention smarter, not harder. Platforms like Tines can automate log routing based on severity, asset context, or alert type to ensure that high-value data is stored exactly where it’s wanted. For instance, the JSON code below configures Tines to store data in the appropriate storage location based on asset criticality and confidence score.
{
"hot_threshold": 80,
"warm_threshold": 50,
"storage_tier": "{{#if (or
(eq asset_criticality 'high')
(gt confidence_score hot_threshold)
)}}hot
{{else if (and
(eq alert_type 'anomaly')
(gt confidence_score warm_threshold)
)}}warm
{{else}}cold
{{/if}}"
}This logic:
Sends high-confidence or high-criticality alerts to hot storage.
Routes medium-confidence anomalies to warm storage.
Pushes low-value logs to cold archives.
Tines can then forward each log to the appropriate S3 bucket, SIEM tier, or archival system which ensures your retention strategy scales with purpose and not volume.
Final thoughts
Network detection and response are only as effective as the practices behind them. Simply deploying an NDR solution won’t meaningfully improve security posture unless it is properly integrated, tuned, and operationalized.
To achieve the highest level of performance, it is best to treat NDR as a system, not just a sensor. This can be done by leveraging orchestration to reduce manual overhead, correlating across data layers to enhance coverage, and refining detection to focus on what matters most. These best practices reflect hard-earned lessons from real-world deployments. Whether standing up a new NDR stack or refining a mature environment, the path to success starts with deliberate design.