Security operations refers to the people, processes, and technologies responsible for detecting, analyzing, and responding to cybersecurity threats within an organization. Effective security operations center (SOC) teams work around the clock, using manual effort in conjunction with leveraged automation to identify malicious activity and disrupt cyber threat activity, all while minimizing business impact.
While some companies have multi-million-dollar security tools in place, tools alone are not enough. Too often, organizations invest millions in tooling only to leave it all misconfigured; this can open the door for a ransomware attack that costs the company millions. Effective security operations are about how the organization’s tools, processes, and operators come together to drive measurable risk reduction. It requires alignment with business goals, the right organizational model, reliable telemetry, automation where it matters, and continuous feedback loops.
The sections below describe the essential components of security operations along with best practice guidance for teams looking to enhance their security strategies. Note that this article focuses on technological cybersecurity operations, not physical security operations. While physical and cyber operations often intersect, the scope here is limited to the digital side of security ops.
Summary of key security operations center
Integrate with organizational strategy
In a well-run operation, security operations exist to serve business outcomes. That means delivering measurable risk reduction in areas that affect brand reputation, regulatory posture, and the ability to operate without disruption. Ultimately, security operations are a form of technological risk management and should fit into the greater enterprise risk management strategy of an organization.
Start by identifying the laws, standards, and contracts that govern your business based on the activities you perform. The table below gives you an example of what this might look like:
After going through this exercise, create a RACI matrix with other stakeholders. The SOC likely won’t be responsible for all objectives, but a good SOC can play a part here by acting as a “consultant” to other business stakeholders who may not have the security or technological skills. After identifying the SOC's role within the greater organization, then transform each obligation into concrete processes that the SOC team can execute: logging, detections, retention, escalation, and notification.
If you’re public, hard‑code your SLAs into the incident response platform so they line up with statutory timelines. If you handle PCI or HIPAA data, ensure that you are getting the right telemetry from these crown jewels so that you can actually see behavior. You want telemetry that gives you real detections, usable hunting data, and the artifacts incident responders need. If you sell to the public sector, map SOC processes directly to NIST controls, show the control, show the procedure, show the log source, show the proof. That’s how you map operations with obligations and become a revenue enabler.
When security integrates with the business at this level, it stops being a cost center and becomes a core part of the business. You start showing ROI on tools, headcount, and processes that were once seen as overhead. That shift earns executive buy-in and builds the case for scaling security the right way. The SOC stops burning hours on false signals and rabbit holes and starts reducing audit findings, accelerating enterprise deals, and hardening the systems that have value. That shift earns executive buy-in, and with it, the budget and support to scale security operations effectively.
Choose a suitable security operations model
There’s no universal blueprint for building a security operations function; the right model depends on your business stage, threat model, risk appetite, and internal capability. What matters is having an approach that aligns with your needs, not someone else’s maturity curve.
Three common models are covered in the sections below.
In-house (dedicated SOC)
This model gives you full control over your security operations. It’s resource-intensive, but if security is central to your business model, it’s often the right investment. Here is how this approach plays out in terms of requirements:
People: You’ll need to hire and retain skilled engineers and analysts across multiple functions, including detection, incident response, automation, and infrastructure. Expect on-call rotations and a need to staff for 24/7 coverage.
Processes: You own the playbooks, tuning cycles, and escalation paths, which allows for tight alignment with your threat model but demands continuous iteration and improvement.
Technology: The organization maintains full-stack responsibility: SIEM, SOAR, EDR, threat intel platform, log pipelines, etc.. You architect and tune every piece.
Risk mitigation: High. You get deep visibility and fast, contextual response, but risk shifts inward, so your success depends on internal execution.
This model fits companies where uptime, customer trust, or IP protection are existential, like SaaS, fintech, or defense. While challenging, this approach builds a core capability that grows and matures with the rest of the business.
Hybrid SOC
A hybrid model gives you coverage without overextending your team; you keep the strategic pieces and outsource the rest. A typical setup is outlined below (but you can change it to meet your needs):
People: Internal staff handle detection engineering, incident response, and automation. Alert monitoring and triage are pushed to an MSSP or external partner.
Processes: Your team controls higher-tier workflows, while Tier 1 triage and noise filtering are handled externally. Clear escalation paths are critical for positive handoffs in the event of an incident.
Technology: Shared responsibility. MSSP tools may differ from your internal stack, so integration and telemetry normalization become very important and a driver for tooling procurement evaluation.
Risk mitigation: Balanced. You preserve core response capabilities while reducing burnout. Risk comes from handoffs, missed context, or slow escalation, which can introduce blind spots.
Hybrid models work well for scaling teams because they let you maintain leverage where it matters while buying time to build internal maturity.
Fully outsourced (MSSP)
Outsourcing your SOC to an MSSP gives you fast setup and predictable cost, but comes with trade-offs:
People: No internal team is required beyond a liaison role. You rely on external analysts who may not understand your environment.
Processes: MSSPs follow standard playbooks across clients. Escalation criteria, tuning, and feedback loops are usually slower and less tailored.
Technology: Vendors often use their own stacks. Integration with your infrastructure may be shallow, and data ownership can get complicated if there is a data governance requirement there.
Risk mitigation: There’s minimal internal lift but also limited visibility and slower response. If compliance is your only driver, it may be sufficient, but if you're facing real threats, the gaps show quickly.
This model fits companies looking to check a compliance box without building internal capability. It's efficient but often doesn’t scale into maturity.
Where to start
The ideal evolution for most security teams starts with a hybrid model. Early on, it makes sense to outsource 24/7 alert monitoring and Tier 1 triage to an MSSP. This gives you round-the-clock coverage without stretching your team thin, and it protects your analysts from the mental drain of chasing false positives or managing noisy tools. Instead of getting stuck in alert fatigue, they can focus on high-leverage work, threat hunting, detection engineering, and building automations. These capabilities require deep knowledge of the IT and business infrastructure, knowledge that an MSSP would not have, and it is most effectively executed by the internal team.
This approach prevents burnout and improves retention. Good analysts want to solve hard problems, not babysit low-fidelity alerts all day. By giving them time and space to level up, you build a stronger team that sticks around, allowing your team to mature quickly. Over time, as your internal processes stabilize and your automation matures, you can start pulling responsibilities back in. Tier 1 alert triage? Automated. Tier 2 correlation and context gathering? Also automated.
Eventually, you graduate into a dedicated model that runs efficiently. At that point, your alerts are tuned, your enrichment is automated, and your response playbooks are tightly orchestrated. Your SOC doesn’t need to run 24/7 with human coverage because the machine handles the noise and funnels the important signals to your team.
This maturity curve is how modern security programs scale: Start pragmatic, grow deliberately, and automate ruthlessly.
Identify your tooling stack
Tooling is foundational to a SOC, but more tools don’t mean more capability. The right stack gives you visibility, speeds up response, and integrates cleanly with your environment, without adding operational drag. A bloated stack introduces friction, slows analysts down, and ultimately increases risk, the antithesis of what the SOC is meant to do.
At the core, you need three things: a SIEM, an endpoint detection and response (EDR) platform, and a workflow orchestration and automation platform. Think of the orchestration and automation layer as the brain, the SIEM as the spine connecting your detections and data sources, and the EDR as the hands and feet that take action on the endpoint.
Your SOC’s speed, accuracy, and scalability depend on how well these components work together. Disconnected tools lead to slower response, fatigue, and inconsistent outcomes. Integrated, low-friction platforms enable repeatable playbooks, faster decision-making, and broader team involvement, enabling junior analysts to be more effective earlier in their careers.
The workflow orchestration and automation platform
This is your central coordination layer, linking the entire detection and response stack, SIEM, EDR, threat intelligence, ticketing, and cloud platforms. It automates the repetitive toil work that burns out your analysts.
Properly implemented, this becomes the automated system of execution for your SOC. Every phishing triage, malware alert, or insider risk investigation runs through defined workflows. This enforces consistency, reduces error, and makes automation accessible to the whole team, not just engineers.
Look for these key features in a product:
Prebuilt workflows and the ability to integrate with any API
Strong low-code/no-code capabilities for building playbooks
Support for bidirectional integrations with SIEMs, EDRs and ticketing and cloud systems
Built-in modules for threat intelligence, human approvals, and scheduled tasks
The SIEM: Your central data and detection layer
The SIEM ingests logs and triggers detection rules, but it’s only valuable if it enables action. You want a platform that accelerates investigation, not one that floods you with alerts. Your SIEM should do all of the following:
Support out-of-the-box ingestion for relevant data sources (the key pillars are network, identity, cloud, endpoint, and application/DevOps)
Offer APIs for real-time data access, alert forwarding, and automated enrichment
Provide mature detection content libraries to accelerate rule development
Include tuning and suppression controls to reduce false positives
Integrate natively with your orchestration platform to support automated response
Choose a SIEM that aligns with your scale, log volume, and detection engineering workflows. If it's hard to tune or automate, it will create more problems than it solves.
EDR: The execution layer at the endpoint
Your EDR is your first line of response at the endpoint, where the kill chain usually arrives at the exploitation stage and where prevention is critical. It needs to go beyond just alerting, so look for platforms that offer:
Full indexing of endpoint activity: processes, file access, network behavior, registry changes
MITRE ATT&CK–mapped detection capabilities
Remote shell, script execution, and on-demand artifact collection
Process tree visualization with real-time event correlation
Built-in quarantine, rollback, and remediation
Memory and forensic artifact collection
DNS and network-layer visibility
Tamper protection and policy enforcement
Support for Windows, Linux, macOS, containers, and mobile platforms
A strong EDR platform becomes your key response capability, letting you act on endpoints without waiting for user reports or manual investigation.
Threat intelligence platforms
Threat intel only adds value when it’s actionable. Pick providers that offer high-fidelity, low-noise feeds that integrate directly into your orchestration workflows. You should be able to plug threat intel into EDR enrichment (e.g., tagging a hash or domain during triage), SIEM correlation rules, and workflow-based auto-blocking or escalation logic. The goal is to enrich decisions in real time, not just generate dashboards.
Breach and attack simulation: Testing what you’ve built
As your SOC matures, adopt a breach and attack simulation (BAS) platform. BAS tools help validate your detection rules, measure response speed, and assess drift in your environment. They’re also valuable during compliance reviews, offering evidence of continuous control testing.
Use BAS results to refine detection logic, harden misconfigured tools, and proactively identify gaps before adversaries do.
Tooling should map directly to use cases
Every tool in your stack should support one or more of these core functions: detection, investigation, or containment. Avoid shelfware by revisiting your tooling quarterly. Reassess whether each tool is actively solving a problem and assess the ROI that it is providing the team and organization. Eliminate unnecessary overlaps or tools that are no longer in use. Finally, prioritize tools that integrate deeply and bidirectionally with your existing tools and IT infrastructure.
How to pick the right tools
When evaluating tools, look in the following areas:
Integration: Do they support native or API-based integration with the rest of your stack?
Usability: Can both junior and senior analysts use them effectively?
Automation-readiness: Do they expose enough data and control interfaces for automated workflows?
Support and community: Is there good documentation, support, and community content to accelerate deployment?
Security posture: Can you enforce RBAC, audit usage, and monitor configuration drift?
A tool isn’t just a feature set but rather a long-term partner in your response pipeline. Choose carefully, integrate intentionally, and revisit often.
Establish centralized telemetry
Accurate detection and response depends on one thing above all: telemetry. If your logs are missing, incomplete, or poorly parsed, your detections will fail when you need them most. Your SOC will waste time chasing shadows instead of stopping real threats, and when a real incident hits, it’ll fail because the logs you needed aren’t there. You cannot defend what you cannot see, and for a SOC, your logs are your eyes and ears.
Collecting and parsing the right data, comprehensively and correctly, is essential. Ingestion gives you visibility; normalization makes that visibility scalable across detections. Without both, detection logic becomes brittle, correlation fails, and response fails. The quality of your telemetry pipeline defines the ceiling for your entire detection and response program.
Focus on the five critical control planes
The most valuable telemetry spans five control planes: network, identity, cloud, endpoint, and application/DevOps. These represent the core attack surfaces in a modern enterprise environment. With all five of these sources integrated into a SIEM, correlation rules can be created to stitch activity across disparate data sources and create high-efficacy detections.
These sources give you coverage across key phases of the kill chain. For example, in a typical phishing-to-exfil scenario:
EDR captures the initial malware execution.
Identity logs expose lateral movement.
Network telemetry reveals the payload delivery.
Cloud logs show data exfiltration.
DevOps logs show data collection.
Ideally, you would like to have your automations disrupt the killchain at the EDR phase, but if you miss any one of these, you lose critical context.
Centralize with a SIEM that can keep up
Once telemetry is flowing, the next step is aggregation. A SIEM becomes the central nervous system of your SOC, collecting logs, normalizing fields, enabling correlation across sources, and providing a platform for real-time detection and investigation. Without this layer, your analysts are stuck jumping between tools.
A capable SIEM lets you normalize disparate data into a consistent schema, correlate events across cloud, endpoint, identity, application, and network, run queries at scale across long time ranges, and create real-time detections.
Normalize and enrich for correlation
Just collecting logs isn’t enough; your data must be normalized, mapped to a consistent format across all sources, and enriched with context like asset data, user roles, and geolocation. Without this, detection logic becomes brittle, and response automation fails.
Build a pipeline that can handle ingestion, parsing, enrichment, and routing in a scalable way. Tools like Fluentd, Elastic Agent, and Cribl are battle-tested for enterprise and cloud native environments. Use these tools to structure logs at the edge, enrich them with metadata, and route them cleanly into your SIEM or data lake.
Tag each event with relevant metadata: hostname, username, business unit, ip, geolocation, etc. Parse logs at ingestion so detection rules can operate on structured fields. Route different log types to different destinations (e.g., SIEM, archive, S3) based on retention or compliance needs. This approach keeps your stack clean and your detections reliable.
Deploying a scalable, open-source stack with OpenSearch
If you're looking for a cost-effective, open-source option, AWS offers Amazon OpenSearch Service, a managed Elasticsearch-forked platform that supports ingestion, search, and visualization out of the box, all while the complex infrastructure management is abstracted as a managed service.
You can build a scalable data pipeline architecture using Fluentd or Fluent Bit for agent-based log collection and routing, Amazon S3 for buffer layer and long-term log storage and replay, AWS Lambda for log transformation, normalization, or custom index management, and OpenSearch as the central search and analysis platform. This architecture gives you a flexible, cloud-native detection platform that scales independently across storage, compute, and query workloads. OpenSearch supports Kibana-compatible dashboards, alerting plugins, and integrates easily into detection engineering workflows.
The image below provides a high-level overview of what this could look like:
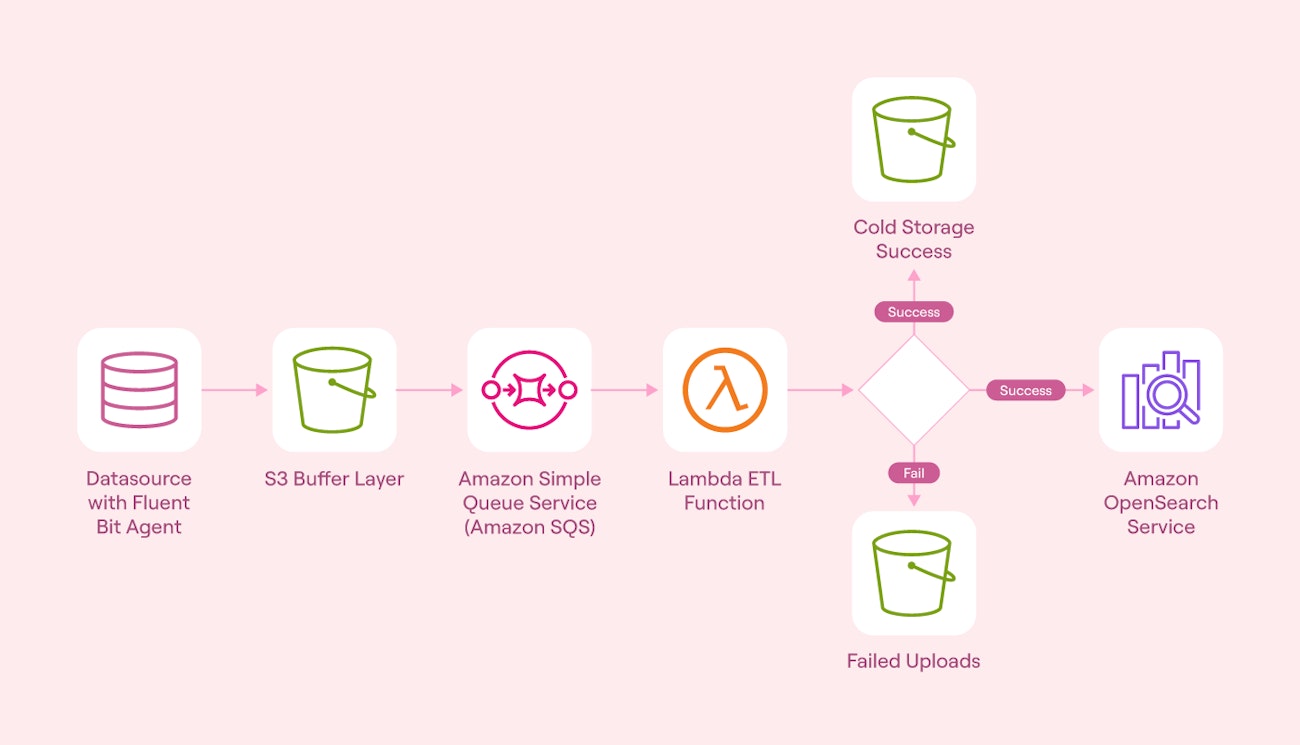
High level overview of a scalable data pipeline architecture (source)
To complete the loop, integrate Tines as your orchestration and automation layer. Tines can ingest alerts from OpenSearch, enrich them with threat intelligence, kick off investigation playbooks, and trigger containment or stakeholder notification workflows. This transforms raw detection signals into full-lifecycle response without needing engineers on call 24/7. The result is a cohesive detection and response system that’s open, extensible, and cost-effective, ready to scale with your team and your infrastructure.

Elastic SIEM to Slack alert enrichment
Enrich high severity SIEM alerts as they are sent from Elastic to Slack, using Tines records.
Leverage orchestration and automation
When done right, orchestration and automation are operational force multipliers that streamline response, reduce manual toil, and make your SOC more resilient without increasing headcount. The goal is to move consistently, with context, and without burnout. That only happens when automation is built into your workflows, not bolted on afterward.
Note the key difference between the two. Automation handles specific tasks without human intervention, like querying threat intel, isolating a host, or tagging an alert. Orchestration connects those tasks into an end-to-end response workflow across multiple tools and systems.
Example: Automating cloud misconfiguration response
Let’s say a cloud security tool detects that an S3 bucket is publicly accessible. Without orchestration, an alert gets dumped into the SIEM, an analyst reads it, logs into AWS, checks permissions manually, looks up the bucket owner, and opens a ticket. With orchestration and automation, the following steps occur:
Trigger: A CloudSec alert fires.
Enrich: A Tines workflow pulls CloudTrail logs, IAM policy data, and asset metadata (owner, business unit, criticality).
Evaluate: Logic determines whether the bucket contains sensitive data or is in a production account.
Execute: If the risk is high, the workflow locks down permissions, alerts the owner, and files a JIRA with evidence attached.
Every step is recorded for auditing and reporting. This turns a 30-minute task into a 30-second decision, one that runs the same way every time, and does so while your analysts enjoy their evenings.
Find & remediate publicly exposed S3 buckets with Wiz
Query Wiz's Cloud Configuration Findings API for exposed public access to S3 buckets. If a public S3 bucket finding is found, create an issue within Jira, send an alert via Slack, and include a remediation prompt within the Jira issue to apply the appropriate block access policy to the S3 bucket.
Tools
AWS, Jira Software, Slack, Wiz
Pick the right first use cases
Start where the manual pain is obvious and the risk of automating is low. Look for high-volume, repeatable tasks that burn time without adding insight. Here are some good places to look, but ultimately this will differ for every environment, and you might have a better use case based on your operations.
Design playbooks like production systems
A good playbook is not a one-off script; it’s a reliable and repeatable system. Make it modular, testable, and observable, as follows:
Trigger: Define a clear input, such as an EDR alert, phishing report, IAM policy change, or cloud drift event.
Enrich: Pull relevant context from threat intel, cloud metadata, identity logs, or the CMDB, or even leverage an LLM for context summarization.
Evaluate: Apply business logic. For example, if CVE ≥ 9.0 and asset is internet-facing → critical.
Execute: Take action, update tickets, notify stakeholders, block IPs, snapshot workloads, or isolate hosts.
Log: Every step, decision, and outcome should be auditable and available for post-incident review.
The sooner you operationalize this mindset, the sooner your SOC becomes fast, consistent, and built to grow.
Continuously assess SOC effectiveness
A high-performing SOC isn’t measured by how many alerts it closes—it’s measured by how effectively it reduces risk. That means tracking outcomes, not volume.
Ask the right questions:
What risks were remediated this month?
What gaps in visibility were closed?
What techniques were detected and stopped?
Measure with the right KPIs
Operational metrics help you assess efficiency and coverage. Focus on these:
Mean time to respond (MTTR): Are you resolving incidents fast enough to contain real damage?
False positive rate: Are your detections wasting analyst time?
Analyst throughput: How many high-quality cases can your team handle daily or weekly?
These numbers are useful, but only if they tie back to risk reduction. Don’t just track them, act on them. Seeing an alert create a spike of false positives? Make sure the alert is tuned or no longer in the response queue.
Use adversary emulation to validate detection quality
Testing against real-world threats is what sharpens your detection program. Red teaming, purple teaming, breach attack simulation, and automated adversary emulation are important feedback loops that show you exactly where your visibility breaks down and where detections are missing. These exercises surface gaps in coverage and logging, especially across control planes like identity, endpoint, and cloud, that don’t always get the same attention as network or EDR. They also force collaboration between detection engineers, automation engineers, and incident responders to close those gaps in a way that’s sustainable and scalable.
Detection as code
Detection logic should be treated like any other software artifact. Write detections in structured formats like Sigma, store them in version control, and apply the same development standards you'd use for production code. Use tools like Atomic Red Team and SCYTHE to test detection coverage in controlled environments, then validate detections through red and purple team exercises. Ideally, all of this would live in an automated CI/CD pipeline, so detection logic is continuously tested and deployed with confidence. This gives your team the agility to evolve detection logic as attacker techniques change instead of lagging months behind. Detection as code transforms detection engineering from a one-off task into a repeatable, testable, and scalable discipline.
Run maturity reviews using MITRE ATT&CK
To evaluate how effective your detection and response program really is, use MITRE ATT&CK as a structured lens. Map every detection and incident response case to specific TTPs in the framework. From there, build visual MITRE TTP heatmaps to track gaps across your control planes. Then overlay that with live IR data to identify areas where your SOC consistently sees attacker behavior but lacks strong detections.
If you’re responding to repeated use of a particular TTP, build a dedicated detection for it. Maturity reviews are not just documentation exercises but rather strategic tools for prioritizing engineering effort, driving roadmap decisions, and proving that your SOC is improving in ways that actually reduce risk.
Tie everything back to business risk
Not every detection needs to be clever to be effective. The privilege escalation logic you wrote in Python might be cool, but if it never fires in your environment, it’s just shelfware. Meanwhile, some of the most impactful detections are dead simple. In almost every enterprise, threat actors are still finding passwords in cleartext, stored in logs, buried in config files, or captured in network traffic. It’s one of the easiest wins for lateral movement and privilege escalation that are observed in almost every incident response scenario.
Build a detection for cleartext passwords, even if it's noisy. Pair it with a playbook that alerts your team, disables sharing from the exposed system, and kicks off a credentials rotation. This alone closes off an entire class of attacks.
Here are some other high-value detections that are just as unglamorous but still critical:
Unauthorized USB usage: This can be a sign of insider threats, data exfiltration attempts, or poor device hygiene. Flag and investigate any removable storage mounted on high-sensitivity assets with a large amount of data transferred.
MFA fatigue or push spam: A spike in MFA prompts from a foreign IP might be the only warning you get before an account is compromised. Build detections that correlate push attempts with geo anomalies.
These detections aren’t complex, but they catch real abuse in the wild. If a detection doesn't reduce the likelihood or impact of an attack, it’s not helping. Every signal your SOC tunes or automates should tie directly to protecting revenue, reputation, or operations.
Conclusion
Security operations connect risk, revenue, and resilience. Whether you’re building an internal team or scaling through a partner, the goal remains the same: Reduce risk in ways that matter to the business.
In this article, we looked at what drives the SOC: brand protection, regulatory pressure, customer trust, and revenue enablement. But understanding these drivers isn’t enough. You have to design your tooling, processes, and team structures to reflect them. That means aligning playbooks to compliance frameworks. Mapping telemetry to attack surfaces. Choosing models and automation strategies that scale with your risk profile.
A modern SOC is a responsive, intelligence-driven engine that detects threats early, responds with precision, and proves its value at every turn. That only happens when you engineer for visibility, consistency, and control from day one, and continuously iterate to keep up with both attackers and business evolution.
Security operations, done right, become a strategic asset. Build it that way.