Imagine getting confronted with this situation. A user from the finance department logs in from an unusual location at 2 am, and at the same time, a firewall detects suspicious outbound traffic to an unfamiliar IP address. Moments later, your email gateway flags messages sent to that same department. As the attack unfolds, you find yourself scrambling to catch up, wondering how your powerful, expensive cybersecurity system failed to keep up.
The problem isn't that your tools failed; it's that they didn't work together. Endpoint alerts appeared in one system, firewall logs in another, and email alerts in a third. By the time your team connected the dots, the attacker had already stolen sensitive data.
This is where extended detection and response (XDR) changes the game. XDR integrates detection and response across endpoints, networks, cloud, email, and identity into a single platform, providing a comprehensive view of threats and enabling quick, automated responses.
This article shares best practices for implementing or maximizing an XDR platform. By the end, you'll have a practical plan to use XDR to streamline processes, accelerate responses, and strengthen your security against modern threats.
Best practices for extended detection and response (XDR)
Centralize telemetry
Visibility is the foundation of any effective security strategy. It is the only way to get the data required for event correlation and incident response. Without it, you are flying blind, and you will never be able to build an effective detection and response system.
Extended detection and response (XDR) makes visibility even more important because it is more than just “advanced” endpoint detection and response (EDR). Instead, it encompasses every component of your compute infrastructure. To be effective, it requires a centralized telemetry system.
To understand why this is the case, consider the Emotet/TrickBot/Ryuk triple threat flow visualized below.
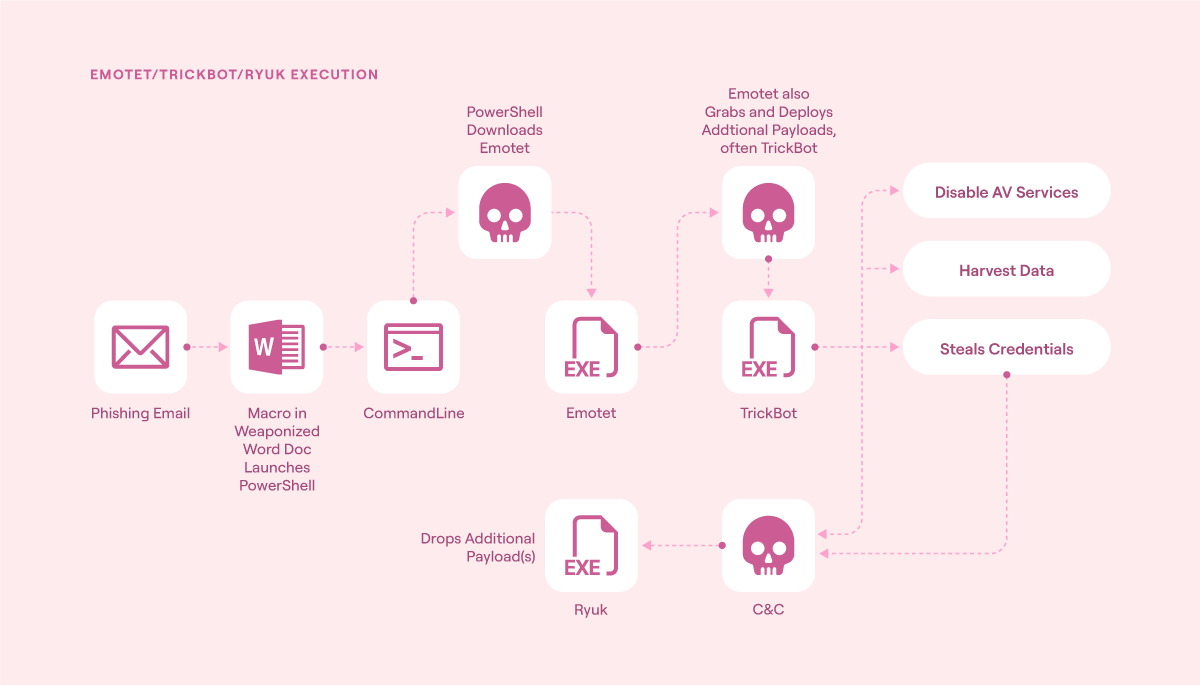
Emotet/TrickBot/Ryuk execution flow (source)
This attack used a series of events, starting with a phishing email, to compromise and ransom target networks. First, it traversed an email gateway, then it progressed through one or more endpoints, expanded its foothold, and then moved laterally across a network. Over time, the adversary identified high-value servers and launched crippling malware attacks. Throughout the compromise, command-and-control nodes allowed human adversaries to direct the attack.
During the period when this threat actor was active, the only way to detect it was by correlating each event across time, infrastructure component, and attack stage. Put another way, the starting point for successful detection and response to this threat actor was a centralized telemetry system that collected events from all impacted assets. Without this insight, it was impossible.
Getting your centralized telemetry right, then, is critical. It needs to cover every aspect of your compute environment, normalize data around a common information standard, and ingest at a speed that keeps detection and response activity near real time.
In most cases, this is done via a partnership between you and your engineering teams. They will take care of things like ingestion speeds, load bearing, and storage requirements. Meanwhile, you need to establish the telemetry metadata and sources to ingest.
If you don’t have an existing automated system that does this for you, list the infrastructure components in your environment and the types of information you will need. This will become a living document that you can update as your infrastructure and requirements change. The table below shows you how to do this, starting with a list of common infrastructure and event types. You can extend this as needed.
Leverage intelligent workflows
In many ways, extended detection and response is a specific application of intelligent automation that is designed to augment human effort. XDR allows organizations to maintain decision superiority over adversaries and operational control over infrastructure.
Doing XDR well, however, is far more complex than simply plugging in an intelligent workflow platform. It requires a disciplined approach to translate your extended detection and response goals into intelligent automation outcomes. Here’s how you go about doing this.
Define automation risk tolerance
First, you need to understand and define your organization's automation risk tolerance. This defines the level of automation that the organization will accept in your XDR capability.
For instance, imagine an extended detection and response system that automatically isolates a cloud endpoint when a phishing email is detected, such as in the workflow below. If your organization prefers a highly automated approach to XDR, the workflow below would be an immediate win. However, if your organization prefers a human-centric decision-making approach, the workflow below is unlikely to be accepted. Notably, the decision has nothing to do with the technical limitations of a given platform and everything to do with the organization's automation risk tolerance. Without knowing these levels, you will be unable to meet your organization's objectives, regardless of your tech stack.



Isolate and take a snapshot of an instance in Google Cloud
Isolate and take a snapshot of an instance in Google Cloud that may be compromised. This quarantines a host and create a forensic disk image for investigation.
Develop an integration process
Next, you need to make sure you have a clear workflow development pathway. It must define a robust process for converting automation ideas into fully implemented XDR workflows while mitigating unintended consequences and errors.
The most effective way to do this is to mirror your existing engineering processes. This aligns your automation efforts with existing business structures and helps ensure a smooth transition between your extended detection and response capability and any partner engineering teams.
An example of a simple process is laid out in the table below if you need a starting point.
Systematically integrate workflows
Finally, approach your intelligent automation journey systematically. Instead of tackling every automation all at once, focus on choosing small, simple automations that offer immediate benefits. As your capacity and understanding grow, target more complex workflows.
Approaching your automation journey this way is important for two reasons. First, it helps your operational teams build confidence and familiarity with automations. Second, it feeds back into your stakeholder engagement process from the first step.
Correlate events
In modern cybersecurity, the only way to detect advanced threat actors is through multi-event correlation. As seen in the Emotet/TrickBot/Ryuk triple threat example earlier, this is the only way to connect disparate events to identify malicious activity.
Unfortunately, many organizations continue to rely on manual effort to perform this correlation. The result is as predictable as it is disappointing: Critically overloaded analysts and advanced threat actors running wild in corporate networks.
The reality is that if you’re not willing to automate correlation, you will never catch advanced persistent threats. You will always be limited by the cognitive capacity of your analysts and their ability to remember disparate pieces of information across shifts, events, and investigations. This is completely unscalable, and from a human perspective, unreasonable.
A far more effective solution is to leverage the capabilities of your extended detection and response system. The subsections below show you how to do this.
Link detections to TTPs
Start by linking every detection to an adversary tactic, technique, or procedure (TTP). In the rare instances where there is no TTP link but the detection is important, make sure it is either thoroughly documented or passed to a different, non-security team.
Doing this focuses your XDR system on the observed adversary action correlation. It moves you away from theoretical, abstract attack concepts and frames the system around specific, quantifiable observations. This helps you codify decisions based on extant events.
An example of how to do this using the Tines intelligent workflow platform and MITRE Att&ck Framework is shown below.


Build and search MITRE ATT&CK semantic index in Elastic
This workflow creates an index of the MITRE ATT&CK framework in Elasticsearch with semantic search capabilities. It enables analysts to efficiently search and correlate MITRE techniques to an alert or ticket description even when exact keywords aren’t used. This enhances threat detection, incident response, and security strategy by providing deeper insights into potential threats.

Enrich incoming alerts
Next, enrich every alert and event with relevant data. This action collates essential data at ingest time, ensuring that every consumer of your alerts, human or non-human, has the full context when the alert is assessed.
For example, consider an alert for anomalous PowerShell spawning. Any investigator or XDR flow would need details such as the parent process chain, asset details, asset owner, and so on. Collecting this information at runtime is the most efficient time to get it, and it ensures that every downstream action is as fully informed as possible.
To do this, create a table of all the alerts you are currently working on. From there, list out the enrichments each alert will need, then use your intelligent workflow platform to start gathering this information. An example of the table, using the PowerShell spawning alert, is below, and you can expand this as much as you need.
Integrate multi-event correlation
Finally, apply multi-event correlation to your alerts. This allows you to link events across time and infrastructure categories, drawing out commonalities at a scale that would be overwhelming for a human-centric approach.
To do this, create a loop in your intelligent workflow platform that feeds each new alert into a self-reflective semantic search. An example of how to do this can be seen in the workflow below.
Receive and correlate alerts from Sysdig
Receive new alert notifications from Sysdig and correlate with other alerts in a time window. If multiple alerts are correlated, send an email notification to the security team.
Automate response actions
One of the unique aspects of extended detection and response is that it enables organizations to move seamlessly from detection to response activities. This is quite different from legacy detection and response workflows, which separate detection from response.
That said, although this improves the efficiency of your security operations, it also poses several challenges. Getting these challenges right is essential, and in this section, you’ll learn how.
Define expected actions
Your first challenge is to define the exact outcomes you expect from your XDR. These are the actions that you expect your XDR platform to take on your behalf, and they need to be consistent with your organization's automation risk tolerance and capability. Without this analysis, you will find that your XDR capability quickly becomes bloated and unusable.
To do this, analyze your existing playbooks and transform them into automated workflows wherever possible. The infographic below shows you how to do this, using a common phishing email response process.
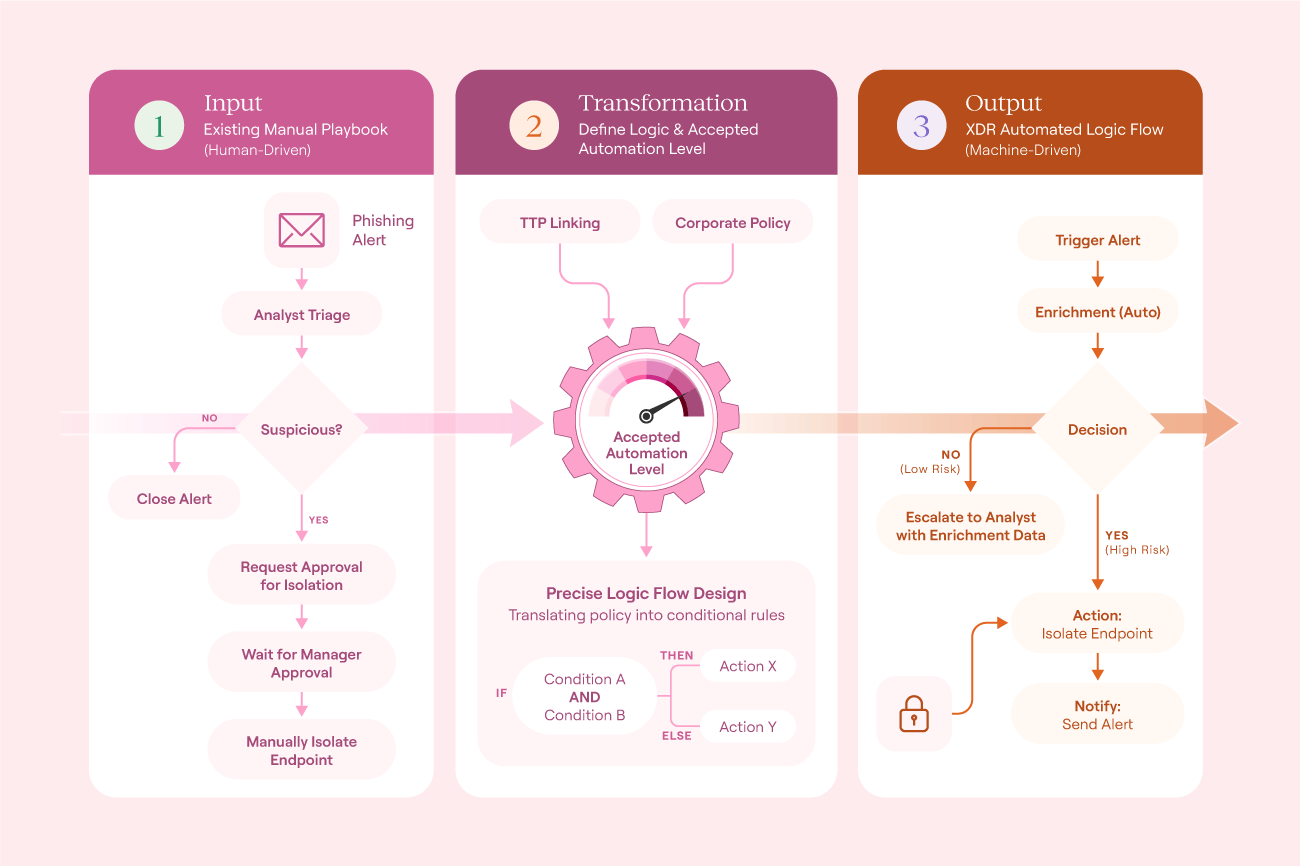
How to move from manual actions to automated processes (source)
Ensure interoperability
Imagine receiving a time-sensitive network-based detection for adversary activity on an endpoint, but your EDR platform lacks the APIs needed to trigger isolation. This would completely degrade your overall cybersecurity impact and defeat the entire point of having an extended detection and response capability. Sadly, this is a common problem for extended detection and response systems.
To avoid this outcome, you need to define what interoperability means for your XDR platform, and more importantly, how to achieve it. You do this by creating a table that specifies each of your tools and the actions they are expected to perform on your behalf. Then, work with your engineering team to translate your requirements into technical specifications. Moving forward, this table should become your interoperability bible, acting as a gate for tool integration.
An example of what this looks like for an EDR platform is contained in the table below, and you should expand this to include everything that is relevant to your organization.
Capture all activity
Finally, the most powerful XDR platform in the world is functionally useless if you cannot track and record the actions it is taking on your behalf. As a result, your final challenge is making sure that every detection, action, and reaction your XDR takes is recorded in a centralized event management system.
For most organizations, this will be their case management system; however, some organizations may rely on other locations. Regardless of where it is stored, you should capture the following information.
Integrate analytics and reporting
As with any other detection and response activity, capturing and recording performance information is essential for XDR capability. It allows you to measure the effectiveness of your program, and, where required, the gaps or issues that need to be addressed.
Ideally, these metrics should contribute to your broader DnR outcomes, such as reduced mean time to detect (MTTD) and mean time to respond (MTTR), as these are the metrics that will reduce the risk to your organization. However, to do this, you need to go beyond simplistic “alert counts” and “automation runs” and instead focus on maturity and efficiency metrics. This allows you to translate your MTTR and MTTD goals into quantifiable segments that you can work to improve.
The table below defines a set of metrics that you can use to do this. Taken together, they provide a deep understanding of your extended detection and response capability and areas to improve.
Last thoughts
In modern cybersecurity, the only way to detect and respond to threat actors is through the use of extended threat detection and response systems. Backed by an intelligent workflow platform like Tines, this is how smart organizations handle multi-event correlations and automated actions at a scale that systematically improves security.
In this article, you learned the best practices for XDR, including setting up centralized telemetry, defining your automation requirements, and measuring success. Each point was backed by practical takeaways and helpful insights that will help you get the most out of your extended detection and response systems.
Remember that while you have no control over the adversaries that will attack your system, you do have control over the effectiveness of your response. Implementing these best practices will significantly increase your ability to respond.