

Introduction
If you've ever been involved in a major database migration, you know just how complex and honestly, nerve-wracking they can be. At Tines, we recently faced the challenge of migrating a customer's dedicated tenant by moving all the customer’s critical workloads running on Tines between two different AWS Regions. All while maintaining 100% system availability. This wasn't just about moving live data, it was about keeping our automation platform running without missing a single webhook or disrupting critical customer workflows.
The project's scope grew beyond initial expectations, requiring improvements to our application and infrastructure. While we encountered several unexpected challenges, from handling gzipped content in Lambda@Edge to managing complex database connection states, these obstacles led to valuable improvements in our system's architecture as well as many learnings.
More than just moving live data
We recently had a customer (we refer to them as “tenants” in our system) deployed on our cloud infrastructure in one AWS region, and they wanted to migrate to another region closer to them. This tenant is one of many we host, but each one can process millions of mission-critical workloads per day via Tines application.
Before diving into the challenges, it’s worth explaining briefly what a “busy Tines instance” looks like. A customer’s Tines application is constantly performing action runs. These are automated tasks triggered by external events like incoming webhooks or scheduled stories which can produce a high volume of data. This level of activity is exactly why the migration had to be seamless: any disruption could impact thousands (or even millions) of automated processes that our customers rely on.
The challenge?
Moving this specific tenant's deployment to a new region without dropping any data or disrupting any of these workloads. Oh, and downtime? That's not an option.
Let me clarify what that actually means in practice:
It’s acceptable if some requests or event deliveries are delayed during the migration.
It’s acceptable if web response times are temporarily slower than usual.
It’s not acceptable to lose or drop any events permanently.
It’s not acceptable to lose any database operations i.e. INSERTs, UPDATEs, or DELETEs.
And above all, we must maintain our data integrity guarantees at all times.
For context, the diagram below provides a high-level overview of our deployment architecture before the migration.
As shown, each tenant’s environment consists of a dedicated AWS Application Load Balancer (ALB) routing traffic to ECS web and worker services running Tines application, which in turn interact with AWS Aurora PostgreSQL for database storage and AWS ElastiCache for Redis to support fast, in-memory operations. This setup is designed to handle high volumes of mission-critical workloads with reliability and scalability.
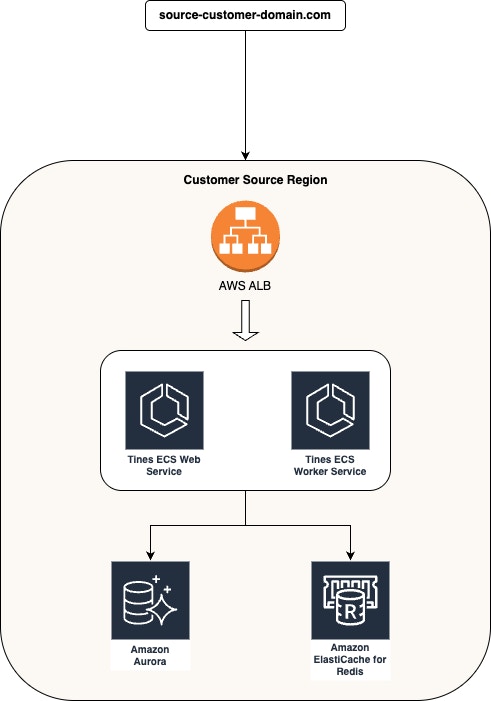
Tines AWS deployment architecture pre-migration
Building a robust migration framework
The diagram below illustrates how requests, data, and replication traffic flowed between the source and destination customer deployments during the migration. As you will see, many components worked together to keep everything in sync and available. In the following sections, we’ll discuss each part of this framework and how we implemented it in detail.
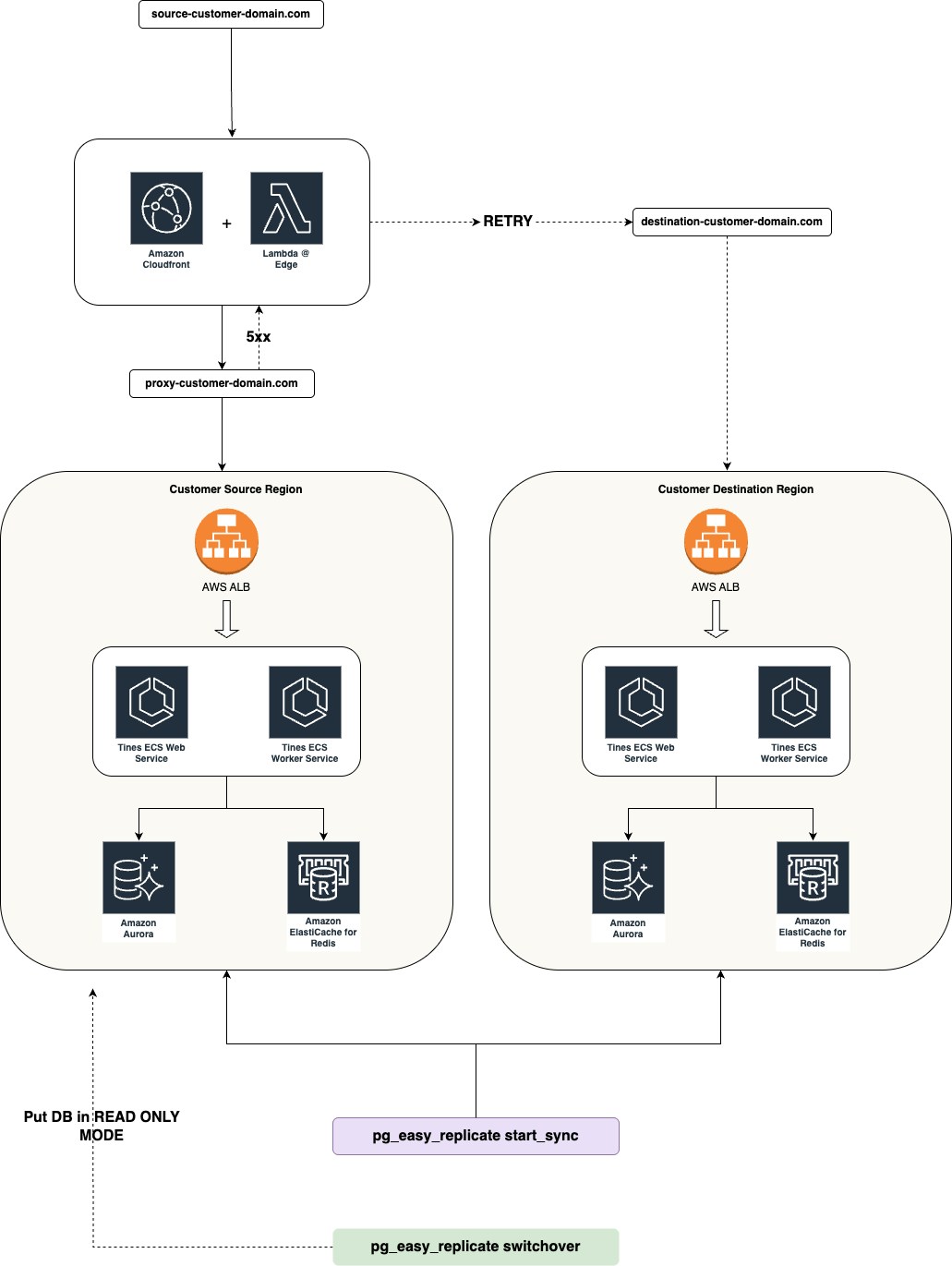
Tines AWS deployment architecture for migration
Smart request routing with Lambda@Edge
One of our biggest challenges was handling incoming requests during the migration. We needed a solution that could:
Route requests to the appropriate environment, specifically, the new region deployment while ensuring no requests are dropped.
Handle failover scenarios
Process both normal and gzipped content
Maintain session consistency
We used AWS Lambda@Edge to solve for this missing connector. Our implementation became more sophisticated than initially planned. We discovered that handling gzipped content and dealing with CloudFront limitations required special attention.
Gzipped content
One challenge we faced was that when our origin server (the Tines app serving GraphQL requests) returned gzipped content, the Lambda@Edge function received the compressed data, which isn’t directly readable or modifiable. This issue did not affect our /webhooks endpoint, as it did not return gzipped responses. To inspect or modify the response body, we had to detect if the content was gzipped and then decompress it within the Lambda function using Node’s zlib library. This added complexity, especially since we also needed to ensure that the final response sent to the client had the correct headers and wasn’t double-compressed or missing the appropriate Content-Encoding.
Header filtering
CloudFront imposes restrictions on which headers can be set or forwarded by Lambda@Edge. Some headers, like Content-Length, Transfer-Encoding, and certain connection-related headers, are either managed by CloudFront or disallowed entirely. We had to carefully filter out these headers in our Lambda response to avoid errors or unexpected behavior. This required extra logic to sanitize the response headers and ensure compatibility with CloudFront’s requirements.
💡 See gist of the Lambda@Edge Function here:
https://gist.github.com/annadowling/4d605be38706184060cd837a37a77397
Database and application synchronization strategy
When it came to migrating the customer’s database, we needed a way to keep data in sync between the old and new regions with minimal disruption. This is where a **blue/green deployment** approach came into play: we maintained both the old (“blue”) and new (“green”) environments in parallel, allowing us to switch traffic with minimal downtime and risk. To enable this, we used Logical Replication. Logical replication in PostgreSQL allows you to replicate data and stream changes (like INSERTs, UPDATEs, and DELETEs) from one database to another in near real-time, making it possible to keep two databases synchronized even as new data is being written. Below, we’ll cover the three key areas we instrumented for the database migration.
Logical replication with pg_easy_replicate
We used pg_easy_replicate, an open-source tool that simplifies setting up and managing logical replication. Out of the box, it handles a lot of the heavy lifting for replication setup very well.

As we got deeper into our migration implementation, we realized we needed some additional features to meet our requirements. This led us to contribute several enhancements back to the project, including:
Advanced logging and debugging capabilities in
pg_easy_replicatefor better visibility into the replication processDevelopment of the
[exclude-tables]command to allow selective table replication, giving teams more control over their migration processCreation of the
[notify]command to send replication statistics to an endpoint on an interval, enabling real-time monitoring
These enhancements not only supported our migration but also improved the tool for the broader PostgreSQL community. The ability to exclude specific tables and monitor replication progress in real-time proved invaluable for managing our large-scale migration with confidence.
At the database level, here’s how logical replication worked in practice during our migration:
Source database
This query shows the replication slot is active, and the increase in retained WAL is expected with ongoing activity.
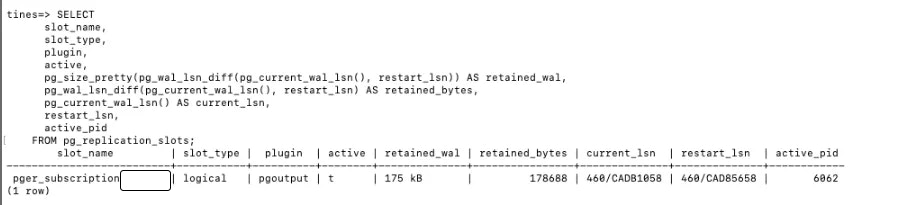
psql query and output for source database logical replication
Target database
On the target, this query shows the received LSN and latest end LSN match, with minimal delay—showing logical replication running smoothly between regions.

psql query and output for target database logical replication
2. PostgreSQL BLOB data synchronization
A challenge emerged when we discovered PostgreSQL 14.10 doesn't support Large Object(BLOBs) replication natively. While logical replication handled most of our data effectively, BLOBs weren't supported yet and Tines stores customer data such as saved images and case attachments.
This required us to develop a custom synchronization solution using a Ruby Sidekiq job. The real complexity involved managing database connections during that sync process.
We implemented a connection switching mechanism to handle the export of the blob data from the source database and import into the target database:
💡 See gist of the DbConnectionSwitcher class here: https://gist.github.com/annadowling/90db3a33a50cb01e2a293ff5c37702d4
3. Reliability improvements for Tines features
A critical part of ensuring zero data loss during migration was improving the Tines Event Transform action runs. Specifically the mechanisms for Throttle and Delay even transformation mode types. Previously, these features relied on our Redis setup for keeping track of the referential IDs which would be read when enqueuing action runs. For the migration, we moved this logic to database-backed persistence using PostgreSQL tables with ActiveRecord in the Rails application.
It’s important to clarify that this change was about how Tines models and tracks references for delayed and throttled events. We treat data in Redis as ephemeral. Any loss of data inside Redis shouldn’t impact application performance or reliability. This is why we didn’t want to invest resources into replicating our Redis data across regions. For us, the priority was to ensure that no event references were lost, and that the timing and sequencing of delayed or throttled events would be preserved, even as we moved between regions.
By enhancing the delay mode & throttle mode to use database persistence, we were able to:
Prevent the loss of any delayed or throttled events during the transition.
Maintain the precise timing and intervals for scheduled and rate-limited event emission, even in the middle of a migration.
This approach gave us the reliability we needed for the migration, without the risk of losing critical event data.
VPC Peering
A pre-requisite for configuring cross-region logical replication was establishing secure, low-latency network connectivity between the source and destination AWS environments. Logical replication in PostgreSQL requires the source and target databases to communicate directly, which isn’t possible by default when they’re in separate VPCs. To solve this, we leveraged AWS’s VPC peering.
Instead of manually configuring everything, we built a reusable VPC peering setup with AWS CDK. This automated the whole process and gave us a template we can re-use for future cases.
Here’s how our CDK implementation works:
Bidirectional routing: The stack configures peering and updates route tables on both the requester (source) and provider (destination) sides, ensuring traffic can flow in both directions as needed for replication and application communication.
Security group rules: We programmatically add security group ingress rules to allow PostgreSQL traffic (port 5432) between the peered VPCs.
Parameterization: The configuration is driven by parameters (VPC IDs, CIDRs, security group IDs, etc.), making it easy to adapt for any customer deployment.
💡 See gist of CDK VPCPeeringConfiguration here: https://gist.github.com/annadowling/6c5abcc6afbf9be45c52562e109aebb6
Migration automation with Tines
Rather than rely on manual processes, we automated the migration through a Tines story. The automation workflow managed four critical phases:
Setup - Resource validation and health check
Replication - Database synchronization and monitoring
Switchover - Traffic routing and environment transition
Post-migration - Cleanup and verification
Each phase included comprehensive error handling, with real-time monitoring through Slack notifications.
Migration story in Tines
The art of switching over: orchestrating failover
One of the most critical parts of our migration was the actual “failover” to the target deployment / database. This was the moment when we switched all application traffic from the old region to the new one. This was triggered via the story using the switchover command input. In our context, failover meant deliberately making the source deployment unavailable for writes, so that all new requests would be routed to the destination (new region) deployment.
To achieve this, we put the source database into READ ONLY mode using the pg_easy_replicate switchover command. This meant any write attempts (INSERT, UPDATE, DELETE) would fail, causing the application to return 5xx errors for those operations.
Our Lambda@Edge function was designed to detect these 5xx responses from the source environment. When it saw them, it would automatically reroute requests to the new region deployment.
This approach ensured a clean cutover by preventing new data from being written to the old deployment, while Lambda@Edge automated the requests failover. As a result, downtime was minimal and the transition appeared nearly instantaneous to users.
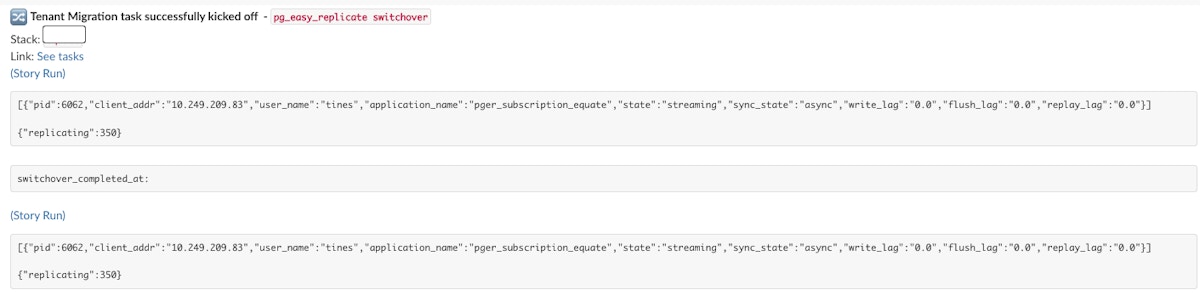
Slack output of switchover monitoring
What we learned
What went well
Our logical replication strategy was robust. We achieved zero data loss, real-time monitoring gave us the visibility we needed throughout, and schema synchronization worked without a hitch. In addition we improved the design and reliability of a number of core product areas including the delay and throttle modes event transform action.

Beyond the success of this migration, the frameworks and automation we built will benefit future projects. With more than 100 PostgreSQL Aurora clusters running in our cloud, the tools, processes, and lessons from this experience will be a huge help when it comes time to upgrade or make large-scale changes across our entire fleet.
We also created a reusable VPC peering setup, making it easy to securely connect databases across regions and pave the way for future use cases. Lambda@Edge request routing also exceeded our expectations. It handled some pretty complex routing scenarios, provided seamless failover, and kept webhook processing running smoothly during the entire migration. You can see clearly in our Honeycomb graph that after the switchover, when the source stack started returning 500 responses (yellow line), requests were seamlessly re-routed to the new stack (green line).
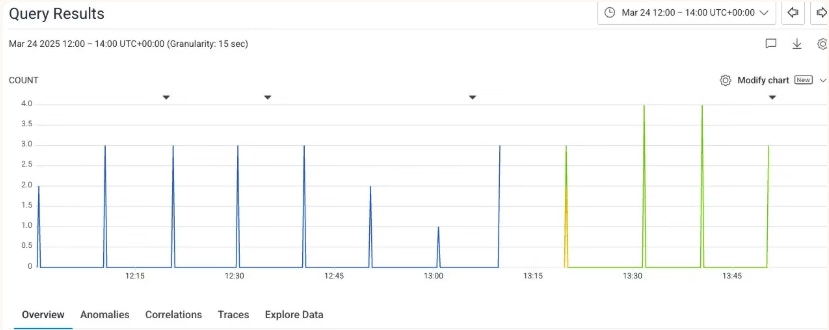
Honeycomb output of monitoring webhook requests during the switchover.
The tricky parts
Of course, not everything was smooth sailing. The infrastructure complexity was real! What initially seemed like a straightforward migration quickly revealed a web of interdependencies. Solving one problem often uncovered two more, and our project timeline stretched as new edge cases emerged.
Some of the most challenging moments came from the database side. For example, we ran into a challenging issue days before the migration: a database migration had run on the source stack but not on the target as a result of a blindspot in our deployment disabling funditonality. Since logical replication doesn’t support DDL(Data Definition Language) changes, the replication subscription worker kept dying and retrying. We had to pause deploys and lock the schema versions on both stacks. Even then, Rails’ schema_migrations table was already synced, so Rails thought the migration had already run on the target and wouldn’t retry it. We ended up adding the missing columns manually, which finally allowed replication to resume. By that point, we’d accumulated nearly 5GB of WAL, so we had to wait for the backlog to clear before we could safely switch over. Keeping an eye on the oldest slot lag metric became essential.
We also ran into an unexpected issue with the BLOB data synchronization job. On migration day, the job that syncs attachments between stacks failed due to unexpected JSON parsing issues, something we hadn’t seen in testing. We ended up “monkey patching” the job via the Rails console in real time, and quickly followed up with a permanent fix after the migration due to time constraints.
Request routing brought its own set of hurdles. Lambda@Edge and CloudFront had their quirks, and handling gzipped content was more challenging than we anticipated. Additionally, we did not support WebSocket requests during the migration. However, since nothing critical in our system relied on WebSockets, we were able to tolerate this limitation without impacting core functionality. Finally, the system we built for this migration now requires ongoing monitoring and maintenance. Good documentation became essential, and with our apps and infrastructure always evolving, maintaining this process would not be straight forward.
Conclusion
This migration taught us that in modern cloud systems, there's no such thing as a "simple" database migration. The complexity of maintaining zero downtime while moving critical customer data pushed us to innovate and improve our infrastructure in ways we hadn't anticipated.
The systems and code we built now serve as building blocks for future improvements at Tines. While the journey was far more complex than initially expected, it left us with more robust infrastructure and valuable lessons about managing large-scale cloud systems.
Final thought: database migrations, it turns out, are less about moving live data and more about making sure nobody notices you're moving live data.