

A frequent, valid objection to the concept of a "full-stack" engineer is that there is just too much to know. No one engineer can consume all 1059 pages of CSS: The Definitive Guide and achieve consensus in an unreliable network. (Especially when it's a rare engineer who can do either of those things...)
What are we left with then? Do we go back to the world of strictly categorizing and dividing engineers based on the technologies or part of the stack they work with? I hope not - there are significant pitfalls waiting for us there too.
The front-end engineer
Imagine you're on a team, working on the CRUD user interface of a groundbreaking new web app for managing widgets. Here's what you have so far:
Next, you're tasked with building out the following simple interface for adding a new widget:
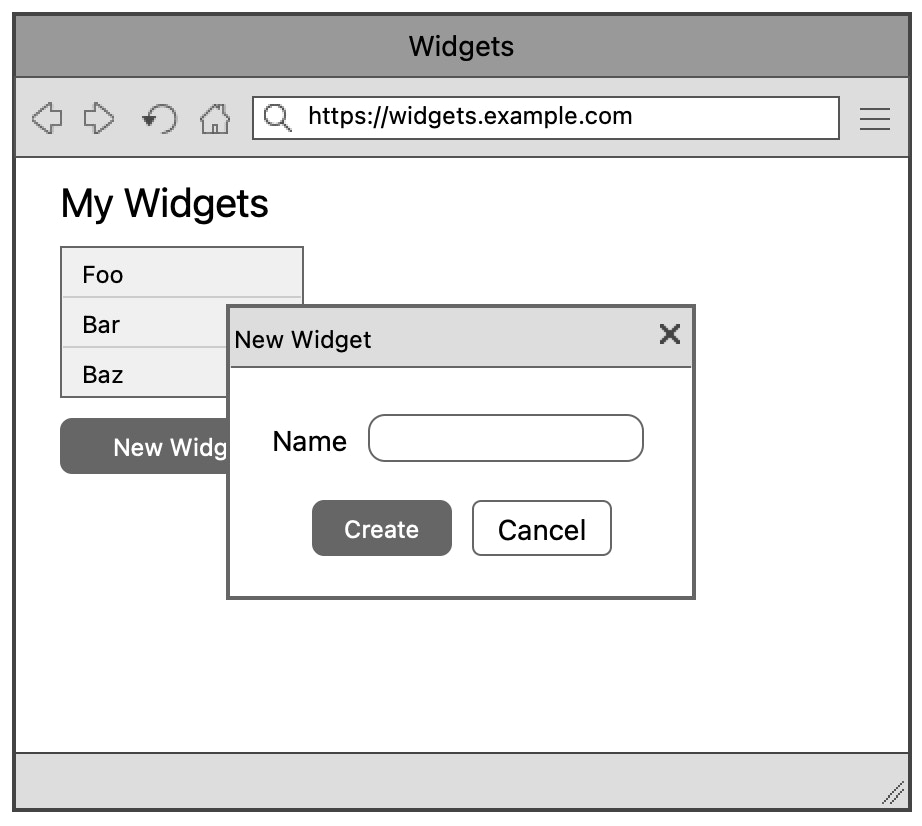
The user clicks a "New Widget" button and gets presented with a popover. If they enter the name and click "Create", the Widget is created. If they hit "Cancel", it isn't.
It's all very straightforward - you think you'll knock it out before lunch. Until you look at the backend API for managing widgets:
There's a
createendpoint. It takes no arguments, creates a widget, and then returns the ID of the widget that was just created. Widgets are initially created with a placeholder name of "New Widget".There's an
updateendpoint. It takes two arguments: the ID of the widget you wish to update and the new name to give it.There's a
deleteendpoint. It takes one argument: the ID of the widget to delete.
It's definitely not an ideal API for the designs you're working towards, but you come up with a clever workaround:
When the user clicks the "New Widget" button you call the
createendpoint.If they enter a name and click the "Create" button, you call the
updateendpoint to set the correct name.If, instead, they click the "Cancel" button, you call the
deleteendpoint.
Problem solved. You build. You launch. Widgets for all!
The back-end engineer
Imagine you're on a team running and maintaining the backend for a groundbreaking new web app for managing widgets. You receive a bug report about mysterious "New Widget" entries showing up despite the user's insistence that they didn't create them:
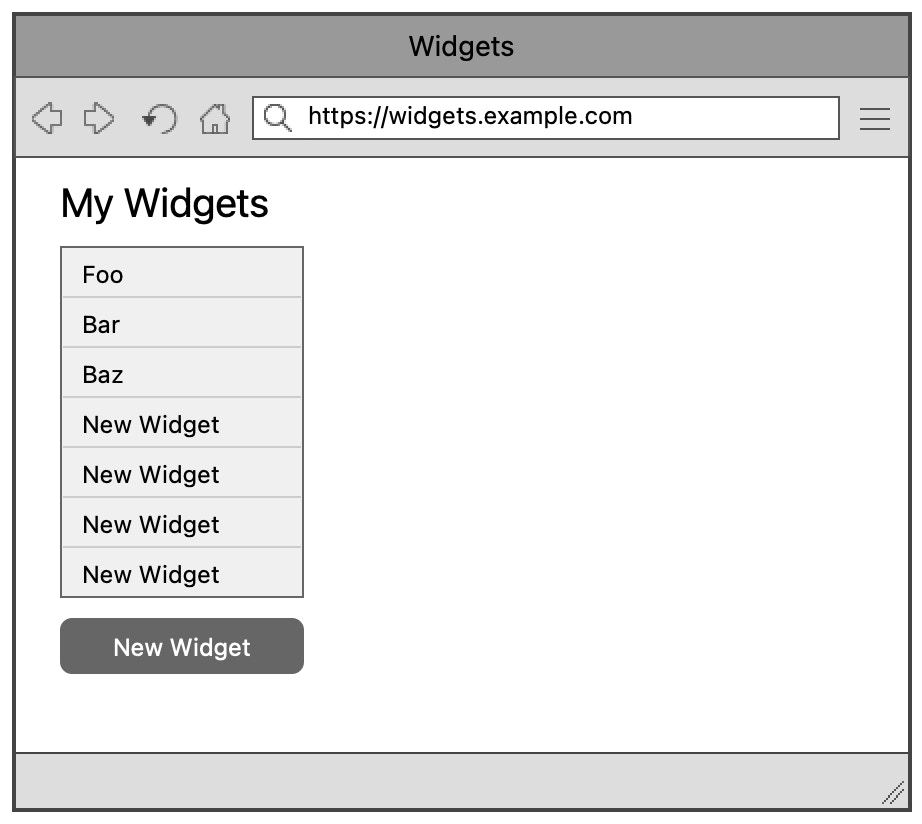
Digging through the logs you see that the normal request pattern is a create followed by an update, to set the name. You reason that, for a variety of reasons, sometimes the update doesn't happen. In those scenarios, the widgets simply haven't been correctly created. They're invalid, broken and users don't want to see them.
It's definitely not an ideal way for the front-end to use the API, but you come up with a clever workaround. You quickly patch the list endpoint driving that view to filter out widgets with the same value timestamps for created_at and updated_at (meaning they haven't been updated since they were first created, and so haven't had their names set).
Not satisfied with the database getting filled up with a bunch of broken entries, you also write a background worker to run every 5 minutes and delete invalid widget rows (those rows with the same value timestamps for created_at and updated_at).
Problem solved. You resolve the issue. Only validly created widgets for all!
The user
Imagine you're a user of a groundbreaking new web app for managing widgets. It's a bit janky. Sometimes ghost "New Widget" entries appear on some screens and reports. Sometimes creating a widget fails, especially if you hit the "Create" button immediately or take a few minutes to pick a name.
The problem
There were quite a few opportunities in that story to avoid the extra complexity and moving parts that the system ended up with, and so to avoid the user’s bad experience.
There's the obvious one: the engineers could put together an API that lines up better with the demands of the UI.
There's also, perhaps, a less obvious one: the engineers could have collaborated earlier with the designer to slightly rejig the UI to fit the API. For example, you could imagine a UI that immediately, intentionally creates a widget with a placeholder name when you hit the "New Widget" button. Indeed, there’s a chance that may actually have been the approach preferred by the designer, but they didn’t know it was possible to build!
When engineers are completely and narrowly focused on just one part of the stack, they will look for solutions to all of their problems in that part of the stack. The far simpler solution, requiring just a small change in another part of the stack - or even an earlier part of the product development process - can go unnoticed.
The curious engineer
If there’s too much for us all to know to be true full-stack engineers, and if engineers being too narrowly focused on just one part of the stack comes with its own problems, what options do we have left?
Instead of saying we need engineers with deep expertise right across the full stack, let’s say that we need engineers who will always look for opportunities to make simpler changes in other parts of the stack. With that restated goal in mind, then the requirement is no longer an amazing pool of knowledge to draw from, it's just curiosity.
A curious engineer will ask "why is the API built like that?", "why is the front-end making requests in that error-prone pattern?" or even, "does the designer know what's possible here?" Maybe the mythical, deeply, and broadly knowledgable full-stack engineer already knows the answers to all of those questions. The curious engineer might only know enough to ask those questions, but has the distinct advantage of actually existing.
The curious engineer will develop their areas of depth, often the areas they’re most interested in, but they'll also be willing and excited to explore unfamiliar parts of the system if that's where their troubleshooting takes them.
The curious engineer will ask the experts in other parts of the system if there’s another way, or when those experts don’t exist, will figure out how to attach a debugger and go learn something new.
And, you never know, eventually, the curious engineer might just end up knowing enough about CSS and CAP to appear awfully like a full-stack engineer.