As cybersecurity threats increase in quantity and quality, organizations increasingly need real-time threat detection and faster incident response. Security information and event management (SIEM) platforms play a significant role in this evolution by collecting security logs, centralizing and automating workflows, and enabling intelligent threat detection and faster response.
However, integrating modern SIEMs into an organization is challenging. Each organization has a unique set of requirements that must be considered, and often, each requirement has its own set of engineering and upgrade processes.
This article provides organizations and teams with a set of best practices for SIEM integration. The article is ideally suited for cybersecurity professionals with a baseline security understanding of concepts like security logs and incident response.
Summary of best practices for SIEM integration
SIEM overview
SIEMs are unified platforms that collect, aggregate, and correlate security data. By leveraging this data, SIEMs provide security teams with a single location to explore, contextualize, analyze, and assess events within their infrastructures. Modern SIEMs extend this functionality further by integrating features such as alerting, data visualization, and reporting.
Conceptually, these activities can be divided into four stages, as shown below:
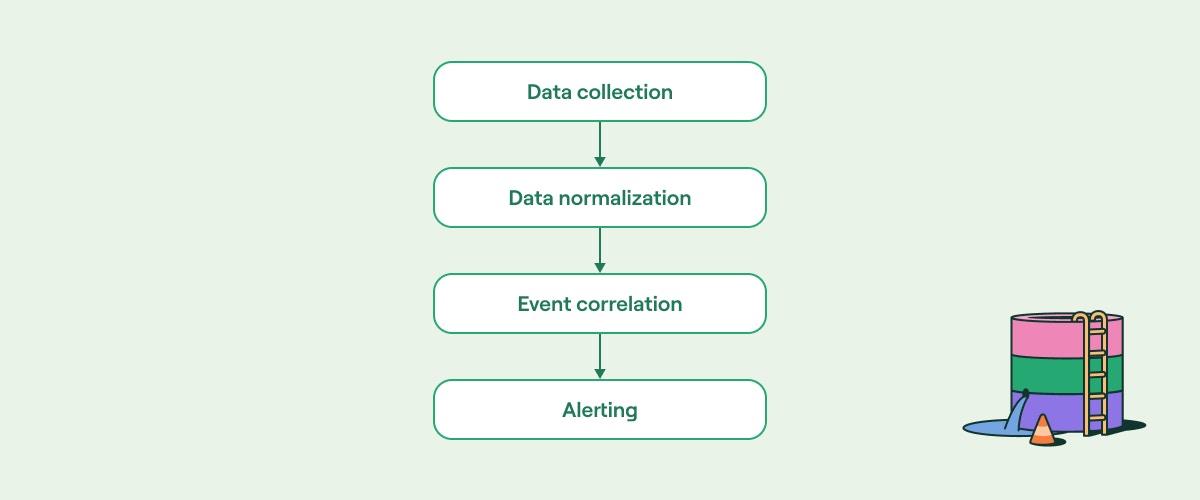
Conceptual components of SIEM operations (source)
Each stage happens continuously and sequentially. For instance, correlating events across time and infrastructure requires that data be normalized. Similarly, any form of alerting beyond single-event specific scenarios requires new events to be correlated against previously known states.
Modern SIEMs also allow users to track and monitor the data they gather (outside of alerting functionality). Often, this includes functionality like customizable dashboards and regular scheduled reports. While this functionality is not covered in this article, it is a powerful way for security teams and executives to get a quick overview of their environments.
The rest of this article expands on the four conceptual stages above by looking at specific relevant best practices.
Workflow orchestration and automation for security teams
- No code or low code - no custom development necessary
- Integrates with all your systems - internal and external
- Built-in safeguards like credential management and change control

Prepare for data collection
Every organization has a unique set of devices and data flows that define its business operations. As each device and data flow operates, it generates a constant flow of security and diagnostic data, a process known as logging. When sufficient logging data is collected, stored, and exposed for investigation purposes, security teams can reconstruct historical events. In turn, this allows these teams to identify and investigate anomalous activity and, in the case of malicious activity, understand what happened.
However, while this concept makes sense on paper, SIEM integration presents practical challenges that organizations must overcome. The subsections below explore these challenges and offer some practical solutions.
Define your data limits
The first challenge for most organizations is figuring out “how much data is enough.” This is an entirely practical question that has almost nothing to do with the devices generating the data and everything to do with considerations such as storage limitations, data scalability, and compute resources.
For instance, this whitepaper estimated that a mid-sized organization with 1,000 employees spread across five sites would generate an average of 190 GB of data per day. Notably, this is just for standard operations and doesn’t even consider companies that may operate dedicated web architecture, such as software-as-a-service (SaaS) companies.
This is an enormous amount of data: Over the course of a year, it would result in over 65 terabytes of data, and some organizations need to store six years of this logging. Even the most efficient databases, with consistent, well-structured data, would require significant infrastructure investments to handle this quantity of data.
For many organizations, this step alone can be overwhelming, but there are practical ways to navigate this challenge and reduce the quantity of data being ingested:
Prioritize high-value infrastructure: Implement a tiered approach to your infrastructure rather than logging every log from every device. In this approach, you collect significant amounts of logs from your critical infrastructure and comparatively fewer logs from everything else.
Use on-device processing to optimize: Rather than relying on downstream processes (such as a SIEM) to optimize your logs, use on-device processing to reduce aggregate data volume. This approach reduces the quantity of data being collected without reducing the quality of your logging.
Differentiate between “cold” and “hot” storage: Not all data needs to be immediately accessible all the time. Reducing the amount of “hot” data (data that is readily available for immediate searching) reduces the load on your storage and compute resources. Note that the exact breakdown of cold vs. hot storage needs to be determined internally based on the organization's regulatory and business requirements.
Each step is independent of the others, so you can choose which combination of these steps is right for your organization.
Determine what data to collect
Next, organizations need to determine what data should be collected. Not every log from every device needs to be collected. Instead, organizations need to answer the question: “Which logs, from which devices, should be collected?”
This complex question is likely to generate significant debate within the organization. Faced with defending their organization from malicious threats, security teams will almost always want every possible log. Faced with ensuring that your infrastructure works effectively and efficiently, engineering teams will want to minimize the operational overhead that effective logging requires.
The problem is that both teams have valid points. For security teams, the ongoing increase of malicious cyber attacks has made even unlikely attack vectors vehicles for catastrophic impacts to organizations. Therefore, security teams feel validated in their demands to collect everything, everywhere, all at once. After all, it’s pointless trying to log something after the event—by then, it’s too late.
Similarly, engineering teams need to ensure that today's infrastructure is running well. They argue that planning for every possible exploit scenario is effectively impossible. Furthermore, doing so consumes valuable resources that could be used to make the current system more resilient and efficient. After all, logging everything is great in theory, but if doing so crashes everything, there won’t be a business anyway.
There is no right or wrong answer to this debate. Every organization's technical solution to this situation differs because each organization's blend of risk tolerance, regulatory requirements, and general business rules is unique. However, there are some practical steps organizations can use to determine a solution that will work for them:
Differentiate between security logs and diagnostic logs: Most devices generate a combination of security-relevant logs and diagnostic logs. Diagnostic logs rarely offer value to security teams and can be eliminated from log collection activities.
Identify security logs that can assist other teams: In many instances, the logs that security teams collect can be helpful for other technical teams as well. Figuring out ways to safely expose this data to those teams can be a great way to get buy-in from those teams.
Define a “necessary logging” framework: Define a conceptual framework that identifies the types of logging necessary for the organization to be effective at security. This focuses debate on achieving the combined objective of a secure organization rather than debating individual log items. Many of the points for this framework are covered in the rest of this article.
Identify data sources
The next step for organizations is determining which devices and data flows should be collected. Although the answer may seem easy—everything!—the reality for most organizations is not quite as simple.
Most organizations just do not fully understand their IT infrastructures. Whether it is due to ineffective infrastructure-building practices, benign neglect, or internal divisions going rogue and creating their own shadow IT systems, organizations generally have enormous amounts of unmanaged systems. The moment a security team begins to map infrastructure, everything turns to chaos.
The knee-jerk response to this scenario is an order from an inexperienced executive like: “Track everything and put it in a database. Right Now.” However, as most security professionals know, creating a configuration management database (CMDB) is an enormous amount of work, with unique challenges and timeframes. Waiting for this to be “right” before continuing with SIEM integration can add months or even years to your deployment timeframe.
In these scenarios, a more pragmatic approach should be taken. Rather than trying to identify the entirety of your infrastructure and then working backwards to identify data sources, organizations can start small and expand outwards.
Start by categorizing the possible devices on your network, then find the people and teams responsible for them. Leverage their experience to start mapping each category of devices and get that data into your SIEM. Then, as more devices are discovered, continue adding them to your SIEM. You will quickly find that a positive feedback loop has been created, and your SIEM integration will proceed by leaps and bounds. Even better, this process can be continued indefinitely until the organization achieves complete visibility.
The table below provides an initial categorization of devices and data flows. While not every organization will have every item in this table, almost every organization will have somewhere to start.
See Tines’ library of pre-built workflows
Plan for telemetry
The final step in data collection is transporting logs to the SIEM. Doing so requires organizations to balance three competing priorities: confidentiality, integrity, and availability (CIA). Security teams want to know that the logs they are viewing can be trusted (integrity), that sensitive information has not been shared with unauthorized viewers (confidentiality), and ultimately, that the logs are available.
Unfortunately, various restrictions compound this challenge. Many devices only support one form of logging or do not allow the installation of third-party software. Sometimes, operating systems have a specific format they use for logs, making it challenging for engineers to modify the data in transit or at rest.
As a result, most organizations use a combination of methods to achieve their goals. For instance, some devices only support Syslog—a highly available, widely supported standard. However, Syslog in its native format is unencrypted, posing obvious concerns about the confidentiality of that data. To get around this, organizations will often wrap their Syslog data streams in TLS encryption, which improves data confidentiality. Other organizations may transport the syslog data to an intermediate location, then stage a combined data stream to the SIEM.
Regardless of the methods used, successful SIEM integration relies on an organization consistently and successfully transporting logs to its SIEM. Each organization must consider which method or methods it will use to achieve this goal.
To help get you started, the table below provides a quick reference guide on different transportation methods and their advantages and disadvantages.
Integrate data normalization
Once an organization has determined what logs it needs and how to get them to a SIEM, the next challenge is normalizing the incoming data. Getting this process right is a multi-team effort that requires significant coordination, collaboration, and planning.
The data normalization challenge
To see this challenge in action, consider one of the most common security events on all networks: the “process start” event. This event occurs every time a process starts on a device or endpoint, such as an application opening, a background security process occurring, a network login happening, etc.
Process start events are incredibly useful when investigating security events. They can provide evidence of persistence on devices, identify infected executables, and provide insight into an adversary's lateral movement. Piecing these events together over multiple devices can provide an in-depth understanding of an adversary's tactics, techniques, and procedures (TTPs).
However, every device and operating system has a different way of recording a process start event. Some devices include helpful information, such as the parent process of the new process, while others don’t. Even event fields that are similar can have different names; for instance, one device might use the term “process ID” while another uses the abbreviation “PID.” The same goes for metadata formats. Some operating systems may record timestamps to the second, while others may go to the millisecond.
Even though this is just one example of one log event, you can already see that the combination of event field permutations is significant.
Standardized event formats
Solving this challenge starts by defining a standardized format for all events. Next, divide this format into a series of “must have” and “nice to have” event fields, so your event format has the flexibility to include devices and times when a full data format is not available. Include as many aspects of the event as reasonably possible, such as atomic, computed, and metadata-related information.
For instance, the process start event could be defined as follows: “A process start event must include the information below.”
{
'event_type': 'process_start',
'event_timestamp': 'YYYY-MM-DDThh:mm:ss.fff',
'process_id': '1379',
'hostname': 'tines_awesome_computer'
}Then, you could define a set of nice-to-have events, like this:
{
'event_type': 'process_start', (previous must have)
'event_timestamp': 'YYYY-MM-DDThh:mm:ss.fff', (previous must have)
'process_id': '1379', (previous must have)
'hostname': 'tines_awesome_computer', (previous must have)
'parent_process_id: '4',
'process_name': 'How to be awesome at automation',
'process_notes': 'Tines is an amazing product that will really help you with automation'
}Now, suddenly, a standardized set of fields for the process start event has been defined. Every engineering team, every device, and every piece of source code knows what data must be recorded and in what format when a process start event is triggered.
Implement logging standardization
Finally, work with stakeholders to implement the new logging standard. Often, this will mean engaging with different engineering teams and the tooling they use to find a way to improve, adjust, or remediate existing logging.
Different teams will require different information to implement the new logging standard. For instance, software development teams building the organization's source code have tremendous flexibility in defining exactly how logs should look and feel. Often, they can take care of normalization when the event is generated. In contrast, the teams that manage an organization's firewalls are limited in how much they can modify source events. Instead, they may need to implement a lambda function or orchestration to transform the generated logs into the correct format.
Be sure to take note of some of the nuances of logging standardization. For instance, in the process start event discussed earlier, a timestamp was given that was precise down to the millisecond. If you are working with an operating system that doesn’t offer this level of precision, you may need to compute or infer the millisecond field before ingesting it into your SIEM. Similarly, you will need to make sure that your timezone and time synchronization activity are accurate for that device, ensuring that your SIEM is receiving information that is globally accurate.
A list of these considerations is in the table below.
Correlate events
At a high level, cybersecurity attacks typically follow a linear, time-bound process. Often referred to as the cyber kill-chain, this process involves some combination of reconnaissance, initial access, achieving persistence, escalating privileges, moving laterally, and then exfiltrating or impacting whatever the initial target was.
Naturally, each of these stages has nuances. Sometimes the adversary lands on a highly privileged account, removing the need for privilege escalation. Sometimes the adversary lands on the exact machine needed to exfiltrate the highly sensitive information they want. However, in general terms, adversaries follow a clear process with discrete tactics and techniques to go from choosing to target a specific organization to their eventual success or, hopefully, defeat by the defending team.
Consider the scenario of an adversary attack leveraging an SMB downgrade attack for initial infiltration. The attack begins with multiple failed Kerberos authentication attempts from a single IP address targeting multiple different user accounts. Eventually, the attacker coerces one of the targeted accounts to downgrade their authentication from Kerberos to NTLMv1 (which is significantly weaker). Next, the attacker uses known exploits against this older, weaker version of SMB to gain access to the targeted endpoint. After a period of time, the adversary is able to access a privileged account and start to move laterally around the network. Eventually, the attacker exfiltrates information from a completely different username and endpoint, achieving their goal.
Although this is a vastly simplified and abstracted attack, several observations can be made. First, when viewed in isolation, it is unlikely that any of these events would trigger an investigation. For instance, most organizations allow authentication downgrades in order to handle things like network outages, older logins, and other availability-related considerations. Second, most of these events can and should be logged. Events like privileged account usage, network connections, and sensitive file monitoring are standard logged items for most organizations. Finally, logging of these events would occur from multiple sources. For instance, the network access attempts would probably generate logs from firewalls and endpoints. Authentication logs would be generated at the authentication server and the endpoints.
With your data collection and normalization in place, these events can be correlated to help determine what happened. When combined with alert fine-tuning (discussed in the next section), organizations can generate more effective and efficient detection frameworks that, in turn, improve their event correlation.
The following subsections discuss the three ways to do this, along with their advantages and disadvantages.
Manual correlation
The first way to correlate events is through manual searching and filtering. This requires a human operator to search and filter tens of thousands of log lines, relying on their intuition and technical skill to identify correlated events. Sometimes this process is augmented by playbooks and pre-saved searches.
For instance, consider the SMB downgrade attack introduced earlier. A manual search method would follow something similar to this logic chain:
Identify that a breach has occurred.
Search for logs from around that time.
Identify that a privileged account accessed the data.
Determine if the privileged account was acting legitimately (in which case it would be an insider threat scenario).
Determine how the privileged account was accessed.
Trace back the lateral movement.
Identify the original privileged account.
Trace this account to the original infected asset.
Identify the use of an SMB downgrade attack.
Identify the original IP.
Manually searching through events has significant downsides. First, it is a lengthy process that can take hours or even days. Second, unless a process exists to capture and record common events, analysts can be stuck running the same searches repeatedly. Finally, this method generates no new alerts, which makes it impossible for organizations to continuously improve their alerting.
However, manual correlation does have some advantages. It is by far the most flexible method, as it allows operators to change and modify their searches as new information is discovered. More importantly, it is often the only way to identify adversary activity that uses novel techniques. For this reason, manual correlation is likely to remain an essential feature for security teams.
Built-in SIEM correlation
The second way to correlate events is using the SIEM's built-in capabilities. Almost all SIEMs have built-in correlation engines that allow users to configure alerts and searches for known risky behavior. Typically, this will combine prebuilt correlations for common suspicious events with ad hoc, user-generated custom search criteria.
Leveraging a SIEM's built-in capabilities allows organizations to instantly level up correlation accuracy. Most modern SIEMs have built-in libraries of adversary behaviour based on well-researched, evidence-based observations, with clearly defined alerting thresholds. More advanced SIEMs even include machine learning algorithms that allow alerting thresholds to be dynamically adjusted based on previously observed “normal” behavior.
However, this method has some downsides, starting with the fact that even the most powerful SIEMs have compute resource limitations. They simultaneously ingest, index, normalize, search, correlate, and alert on vast amounts of data in a constant stream of events. Each new correlation activity compounds this activity, often slowing down the entire SIEM. In addition, leveraging a SIEM's built-in features requires users to conform to specific data formats and ingestion methods, complicating existing data collection and normalization activities.
Orchestration and automation
A third option for event correlation is to leverage external orchestration and automation platforms. With this approach, organizations supplement their SIEM integrations with an external platform that can automatically perform more complex workflows.
Integrating a workflow orchestration and automation platform can be a powerful way to enhance the effectiveness and efficiency of event correlation. It allows organizations to extend correlation to include if-then branching logic based on contextual clues and insights.
For instance, consider the scenario introduced at the start of this section. The final event, data exfiltration, was caused by the malicious use of a highly privileged account. Assuming the account had the correct permissions to access and download this data, automatically detecting and alerting on this event is almost impossible for a SIEM. It relies on significant contextual data to establish whether the account was used maliciously and, if so, what to do next.
In contrast, consider the power and simplicity of this workflow orchestration built with Tines, which does the following:
Identifies an unusual login using standard login alerts
Checks the geo location of the IP for the alert
Checks if the user is online
Confirms with another service (Workday) if that user should be in that location
Alerts the user if a discrepancy is detected
Alerts the security team if an inadequate response is received
Furthermore, this workflow orchestration could be extended to include multiple branching events so that most of the scenario investigation is automated.



Check Workday for unauthorized travel and alert in Slack
Get login events from JumpCloud and Google and enrich the location from the source IP. If the location matches a list of unauthorized travel sources and has not already been registered in Workday, verify the login with the user and their manager. If it is an unknown login, page the security team with OpsGenie.
Community author
Muhammet Tekbicak
Fine-tune alerting
Every cybersecurity professional in an operational role has experienced the catastrophic impacts of an alert flood. Some engineering team, with the best of intentions, makes a change to one of the systems they support, and suddenly, the alert volume skyrockets. Within minutes, the ticketing system shuts down, API thresholds are breached (generating more alerts), and the security team can’t search through the SIEM because resource consumption has spiked to 100%. You can’t know if some adversary snuck in during this time because your entire detection and response system experienced an internal denial of service.
The thing about SIEM integration is that, initially, it takes this scenario and multiplies it by 100. Even though the end result is positive—a powerful, real-time data engine that proactively identifies threats—there will be a period of time when all you will be doing is filtering and fine-tuning your alerts.
Knowing this, it is best to be prepared and generate a plan to work through these initial alert spikes. There are three ways to do this, which are described below.
Allow time for normalization
Every time you add a new category of devices to your SIEM or improve some aspect of your data collection pipeline, allow time for this new data to be normalized. Although the exact amount of time will vary depending on the significance of the change, a good rule of thumb is to allow 30 days for each major change. This gives your security team time to filter out environmental alerts that add no value and your machine learning algorithms time to adjust to the “new” normal.
Create a test index
Once a SIEM becomes operational, it will exist in a constant state of change. New data sources are constantly being generated, and it is infeasible to simply “ignore alerts for 30 days while we all get used to it.”
Once you reach this stage, use your SIEM to create a test index for new events. This index should include all your “normal” and “new” events. Use this index to fine-tune your alerting before adding these events to the main index.
As a side note, most SIEMs allow specific logs to be tagged when ingesting the data. If creating an entirely separate index is infeasible, adding a “test_log” tag to “new” logs and instructing your alerting pipeline to ignore logs with this tag can be a reasonable alternative.
Include feedback processes
Organizations are often so busy working on the technical details of SIEM integration that they forget to include simple feedback mechanisms and processes. For instance, most security operations center (SOC) professionals can immediately spot the kinds of configurations that will generate excessive alerts. They know the protocols and standard configurations for devices in “their” network and what normal looks like. Similarly, during your initial testing and integration stage, it is likely that entire classes of alerts can be eliminated by sitting down each week and reviewing the top 10 alert types.
If your organization does not already have a formal detection engineering process, use this three-stage feedback process:
Individual alert flagging: Create a button or flag in your internal ticketing system that allows any operator to flag the alert as unnecessary. When this button is pushed, operators should be prompted to briefly explain why this alert is unnecessary.
Weekly review board: Create a weekly meeting of direct operational managers to review all flagged individual alerts (or groups of alerts if there are too many for one meeting). Any alerts that are judged to be unnecessary should be passed back into the detection system to be filtered out.
Monthly review board: Create a monthly meeting of senior leaders with the security teams to review the outcomes of the weekly review board. If it is observed that permutations of the same alert type are constantly being filtered, this should trigger a more in-depth investigation aimed at resolving the alert-to-usefulness disconnect.
Phase in orchestration and automation
Adding a workflow orchestration and automation platform to a security capability can significantly impact established workflows. Even though the overall outcome is positive—a faster, more efficient detection and response capability that systematically reduces repetitive, manual steps—the pathway to achieving this goal will have challenges.
Some of these changes will be relatively simple. For example, replacing sections of existing playbooks with the output from an orchestration platform is relatively straightforward. Cognitively, all a security operator needs to do is to skip straight to the platform's output rather than doing the steps themselves. They still have all the contextual information from the playbook, and all the platform is doing is speeding up the process.
However, this may change when more complex scenarios are included. For instance, imagine what would happen if a complex, multi-stage attack is identified, and the orchestration platform simply sends a Slack message like: “look at this problem here.” Most security operators would need more context, which would inevitably lead to them reconstructing the entire event themselves rather than relying on the platform's output.
The same considerations apply to all stages of SIEM integration. Security teams need to trust that the data being collected is valid even when an orchestration platform enriches it in non-linear ways. SIEMs need normalized data to be provided even when an orchestration platform has modified the original atomic data in transit. Event correlation and alerting activities cannot result in spikes of invalid alerts.
To resolve these challenges, phase in your workflow orchestration and automation using the four steps outlined below.
Establish human-in-the-loop thresholds
Every organization has a different threshold for workflow orchestration and automation. Some are happy to automate as much as possible, relying on auto-adjusting tolerance levels to maintain control. Other organizations prefer a more human, hands-on approach, where very few decisions are made by their orchestration platform.
Even though this step is non-technical in nature, knowing and planning for these thresholds is critical. When you get it right, your security teams and other stakeholders will trust the platform and reap the rewards of more efficient and effective security capability.
To establish these thresholds, invest time engaging with critical stakeholders. Using practical examples and replaying previous incidents, explore questions such as: “Would you be comfortable with this platform performing these actions?”
Start with small test cases
Using the thresholds previously identified, start demonstrating small test cases in your SIEM integration. This helps build trust in your workflow orchestration and automation platform as well as helping impacted teams understand the changes that are being made.
Target events and activities that are critical enough to resonate with your target audience but low-risk enough that getting them wrong will have a small impact. For instance, use a workflow orchestration to augment a critical log file, but put it into the SIEM with a “test_workflow” tag. This ensures that the existing SIEM activity isn’t disrupted but allows you to show how using this orchestration could improve the logging file.
Once you have successfully demonstrated 5-10 of these test cases to each of your target audience groups, proceed to the next stage.
Integrate workflow transfers
In this phase, you take the learning from the previous two stages and start implementing workflow orchestration and automation at scale. The goal is to create a repeatable process that systematically reduces manual processes while minimizing any cognitive, technical, or alerting threshold impacts.
You do this by developing a process that:
Identifies workflows that would benefit from orchestration and automation
Develops a solution
Tests the solution
Deploys the solution into production
Checks that the deployed solution is working as intended
Constantly gather feedback
Finally, make sure that you are constantly gathering feedback from your stakeholders on how the workflow orchestration and automation platform is going. Take time to understand what is working and what isn’t working.
This may mean revisiting the initial answers to previous questions; however, in the long run, it will help ensure that workflow orchestration and automation become critical parts of your SIEM integration.
Did you know Tines' Community Edition is free forever?
- No code or low code - no custom development necessary
- Integrates with all your systems - internal and external
- Built-in safeguards like credential management and change control
Final thoughts
SIEMs play a critical role in security operations. When integrated effectively, they operate as real-time data engines that can integrate, correlate, and alert on vast amounts of data from everywhere in the organization.
The challenge is that getting SIEM integration right is not simple or trivial. It requires a systematic approach that allows organizations to identify their data sources, normalize their data against a common standard, and then engage in correlation and alerting activities. Each of these stages requires careful forethought and planning.
However, when done effectively and augmented with workflow orchestration and automation, the results are extraordinary. Organizations find they are finally on the front foot of security, identifying attacks before they become fully blown breaches. Security teams can update correlation and attack identification in real time, minimizing exposure windows and improving their mean time to respond. It is an activity that is well worth the effort and has the potential to radically transform an organization's security posture.