
You’re on-call, it’s 3 am and you’re not really asleep or awake. The background anxiety always peaks during on-call weeks but this time you know there’s something that could ratchet the stress down significantly. Suddenly your phone vibrates, you become fully alert, and as you slowly and apprehensively reach for your phone, your heart sinks. It’s a P1, the adrenaline kicks in and your chest tightens.
But wait, it’s not a widespread outage or attack, it’s a SecOps (Security Operations) ‘white-glove’ executive incident. It’s been almost a year since the previous high-profile incident that few know about, fewer dare mention, and even less know why. You scan the current incident details and remember you have the option to initiate the SecOps IR (Incident Response) and containment playbook from right there inside PagerDuty.
A little smile creeps up the side of your face, you exhale slowly, and your chest becomes less tight. You ACK the notification and click the link to initiate the IR playbook. You get an immediate status update, and you reset the incident to a P3. “Phew, that’s pretty cool...”, you muse to yourself as you proceed to snooze the alert in PagerDuty for 4 hours until your normal 7 am wake-up call. This time you go straight to sleep but just before you doze off, you wonder what other teams could use this sort of automation for any incidents and to standardize their responses, be they new hires or old ‘hats..
But how is this possible? Let’s take a peek at what’s behind this automation.
What is your desired automation outcome?
At a high level, we map out what we want to achieve in a simple sequence. We then use modular stories to tell our integrations what we want them to do (and under what conditions). Let’s query a group of CrowdStrike EDR (Endpoint Detection and Response) actions installed on a group of executive's laptops. We look for high severity detections and then distill them down to truly actionable alerts right inside PagerDuty.
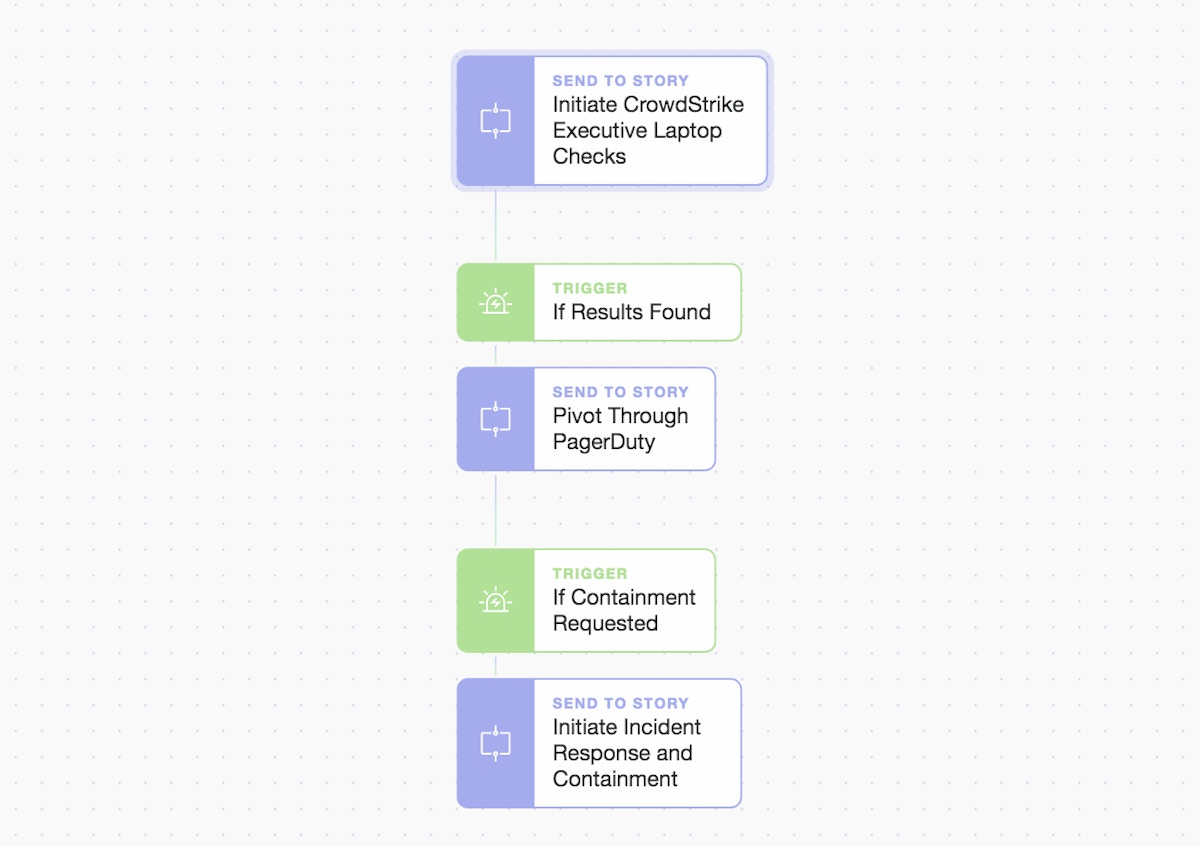
Simple and modular main Story flow
We not only generate the PagerDuty incidents and notifications themselves but add single-click actions to initiate any number of automated workflows from inside the PagerDuty UI (User Interface) itself.
Many teams still want to retain human oversight of certain decisions while automating others. It all depends on whether the scale, velocity and confidence required lends itself to human or machine steps. For human operators, it’s also satisfying and reassuring to remove uncertainty and know exactly what’s next.
Signal from noise
If we quickly dive into the first sub-Story we see a very linear and simple flow that retrieves hosts from a host group. It goes looking for detections within a specific timeframe and above a severity threshold. This flow is basic but can easily evolve and be reused in multiple workflows.
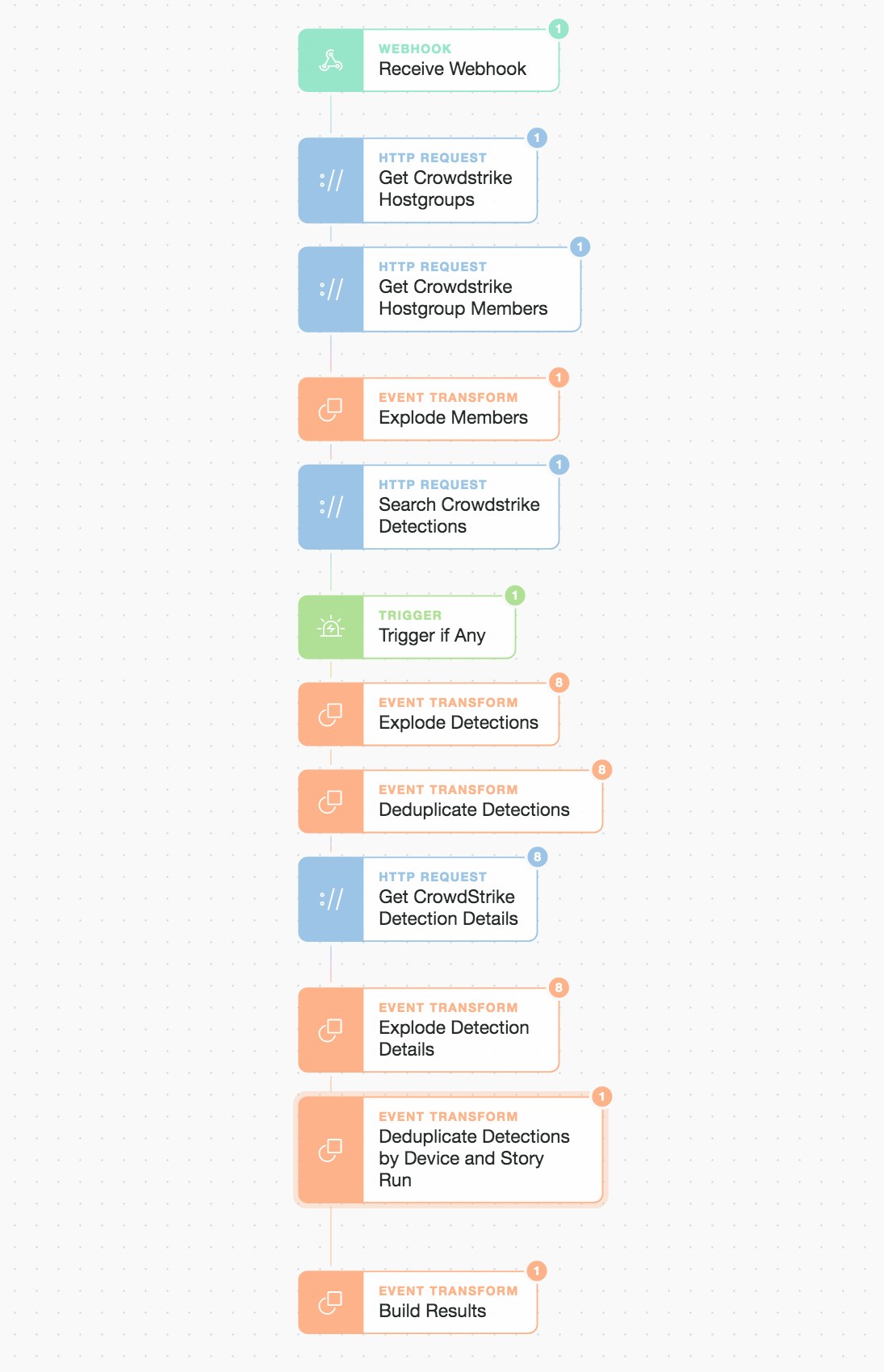
CrowdStrike searching detections by group, severity, and time
We can pass any group name and severity level into this sub-Story and it will build the results for us in a readily consumable manner. We then pass back a range of information including hostname, username, platform type, and device IDs which allow either the engineer or any subsequent automations to make rapid decisions and execute.
PagerDuty for human gate-kept automation
Once we find high severity detections we deduplicate them by host and Story run then pass the details over to our PagerDuty sub-Story to generate a high-priority incident. All aspects of an incident are configurable and we ensure that important attributes are included such as our SecOps escalation policy, incident priority, and relevant service group name.
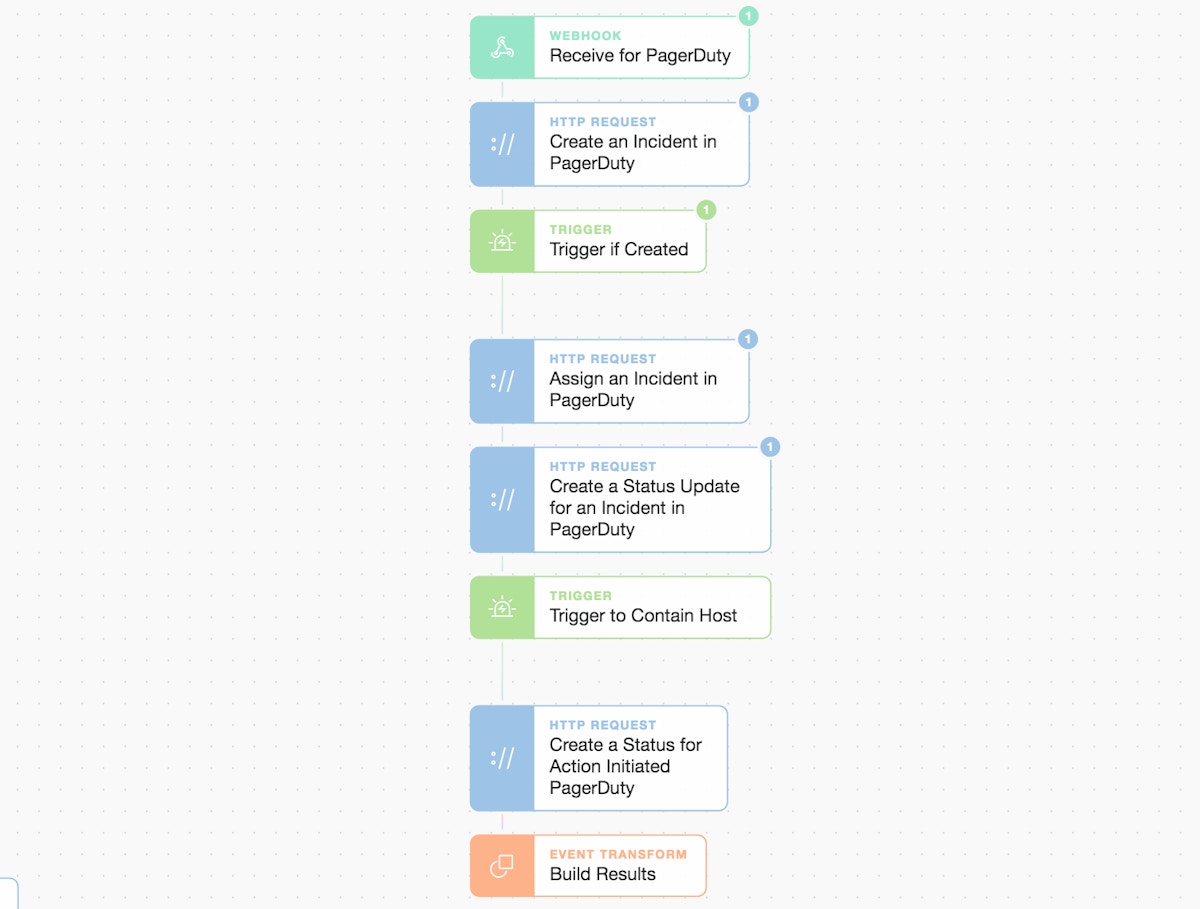
PagerDuty simple gating logic for a decision point
This is where the integration shines, we can actually gate the logic and retain human oversight on the automation workflow.
We include a simple prompt (shown below) in the first PagerDuty status update. It acts as the decision point for the engineer to choose how to respond.
This is still all engaged with from inside the engineer's phone. This feature empowers them to take repeatable, consistent, and predefined actions quickly.
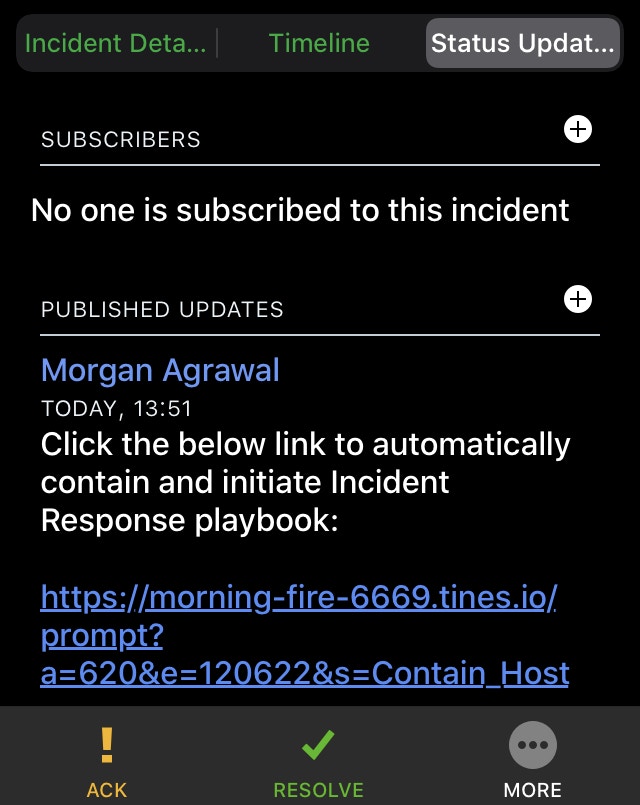
Once clicked, the workflow continues.
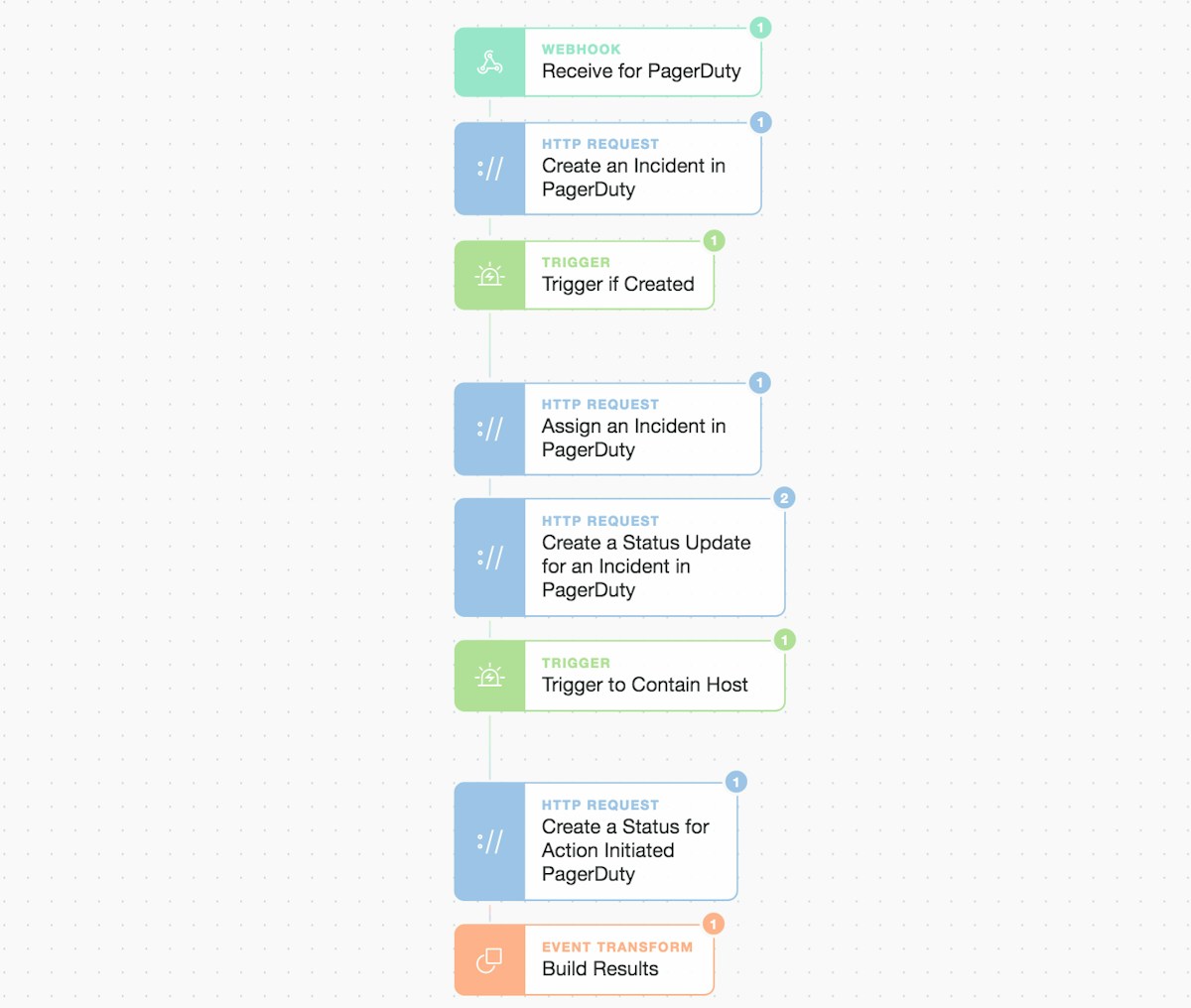
Continuation of PagerDuty workflow due to a manual prompt click
Overall we keep it simple. A singular choice rests with the on-call engineer to either manually investigate or automatically run the Incident Response and containment. If the engineer chooses the automated path, the final sub-Story plays out (below). Story logic could be branched for more complex decision making, to run multiple parallel workflows, or to wait for consensus (all initiated by prompts).
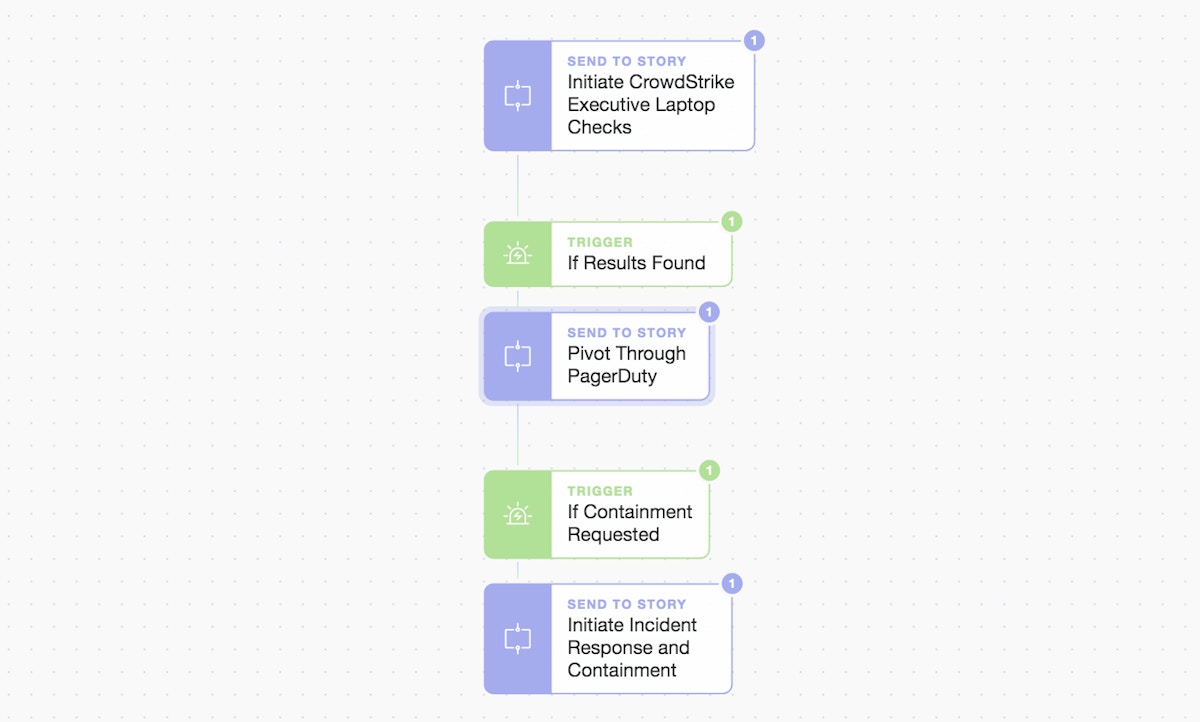
Another look at the primary Story workflow
Better and faster, but not harder!
Once the host is contained we can do mop up and/or further automated investigation in a number of automated ways.
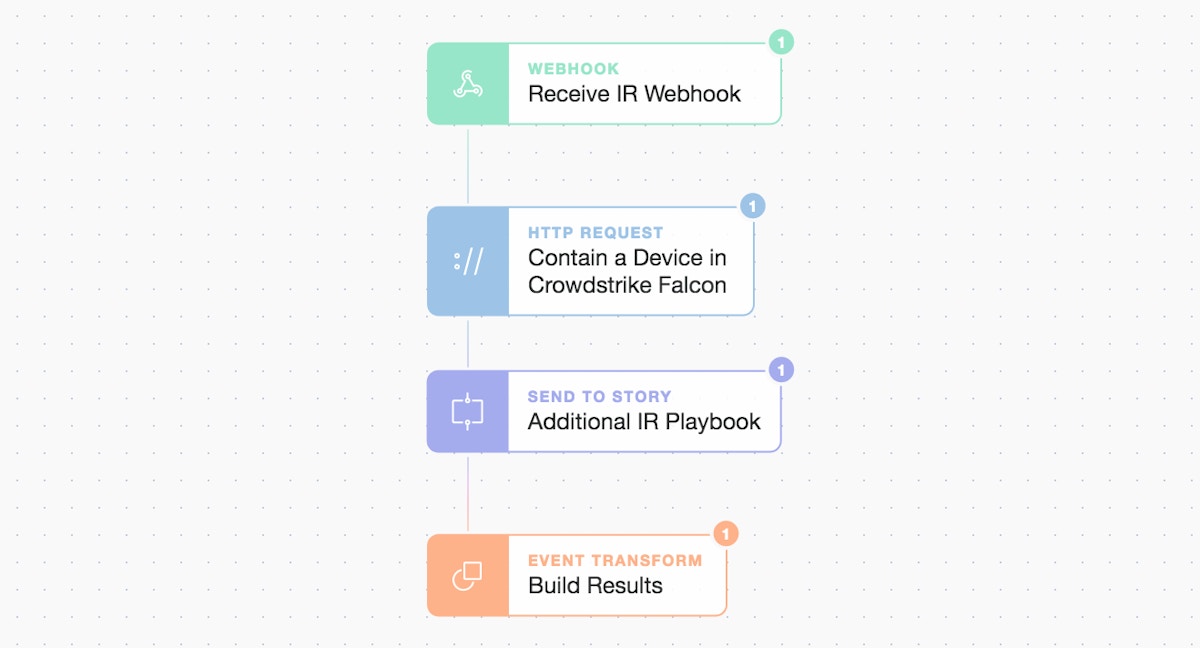
Contain and initiate further IR playbook
Here we initiate another sub-Story after containment called “Additional IR Playbook” but the incident can now be confidently downgraded allowing for a good night’s sleep!
What's your schedule?
Automation never gets tired. We scheduled the main workflow to run every 30mins. It only generates PagerDuty alerts when we find something important. We could trigger the primary Story in a variety of ways such as with a webhook from another platform, system, or Story. The scheduler allows for multiple types of schedules and can initiate a Story at exact times of the day, different days, or even subgroups of either.

Example scheduler for sub-Story initiation
Automation can accelerate many processes and workflows. It can even be a forcing function to help model and adopt best practices. By being prepared and responding faster with greater confidence, your team’s agility and proactivity are increased. This lowers risk and workflows become more consistent and repeatable even while they evolve. As complexity grows and events accelerate, leveraging intelligent automation gives you the edge you need to stay ahead of what’s coming next.
Tip: You can download the above workflows/Stories (Main Story, CrowdStrike Story, PagerDuty Story, IR sStory) and use them straight away in your own Tines tenant or using an immediate free Community Edition.
*Please note we recently updated our terminology. Our "agents" are now known as "Actions," but some visuals might not reflect this.*