

Fair-share orchestration of resources in a tenant, especially in a multi-tenant context is a complex, multifaceted issue. It involves ensuring equitable access to shared resources, preventing system overload, and maintaining optimal performance across all customer workflows.
As more customers build and trust Tines with their most important workflows, (which sees the platform handle over a billion automated actions per week), we recognized that we needed to ensure our platform's scalability. Because of this, we needed to revise our original approach to the platform’s action run orchestration, in May 2025.
Original approach
Our initial approach used a per-story token bucket method, with periodic full refills. Every few seconds each story's bucket would refill to maximum capacity. This original design benefited from:
Ease of use, ease of implementation and easy to debug
The ability to account for long-running action runs, which provided a more accurate reflection of a story’s capacity utilization.
The ability to show capacity promised to a story vs. the reality.
This approach worked well initially, and as demand grew - more customers, more building etc - we saw the opportunity to make execution even more predictable. Our goal was to ensure that every workflow received access to capacity, and less worker monopolization. That means more proactive resource management so customer workflows run predictably, regardless of platform-wide activity, especially in a multi-tenant environment.
Scaling with the customer
Tines uses a queue powered by Sidekiq (simple, efficient background processing for Ruby), PostgreSQL as the primary data layer, and Redis to execute workflows. We call workflows ”stories” in Tines, and when a story is triggered, it creates individual executions of each action in your workflow called action runs. These action runs are processed by a fleet of worker processes.
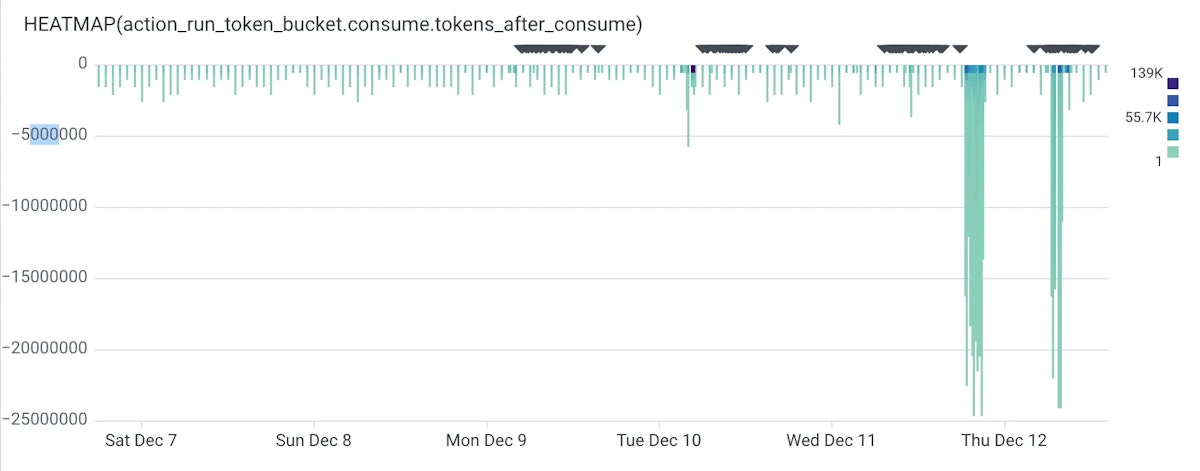
Some stories can flood the queue during spikes (e.g. on the hourly mark):
A story with available tokens could enqueue 100+ action runs at once.
Multiple stories can do this simultaneously.
The queue can then flood, workers can saturate, and execution can become a race.
Some stories can get most of the workers while others can starve.
Furthermore, when tokens are refilled, stories can consume capacity rapidly, creating the spikes you see in the below heatmap.
We recognized that we needed a stronger contract. A bounded concurrency, smooth budget accrual, and explicit backpressure when the fleet is saturated to ensure fairness at the story level.
The goal was not to completely eliminate spikes, but to shape them so the system remained fair and predictable even when busy. We wanted fast stories to remain fast while slow stories appropriately slowed down.
Our approach: fair-share orchestration
Based on our insight we rebuilt our action run fairness around two primary pillars:
A deterministic concurrency gate that limits the share of total workers consumed by any action starts at any moment.
A continuously accruing per‑story budget that caps how much work a story can start, with high‑priority stories (on single‑tenant clusters) getting more worker budget.
Near the hourly clock mark, we temporarily dampen parallelism in multi‑tenant environments to prevent synchronized spikes without impacting performance.
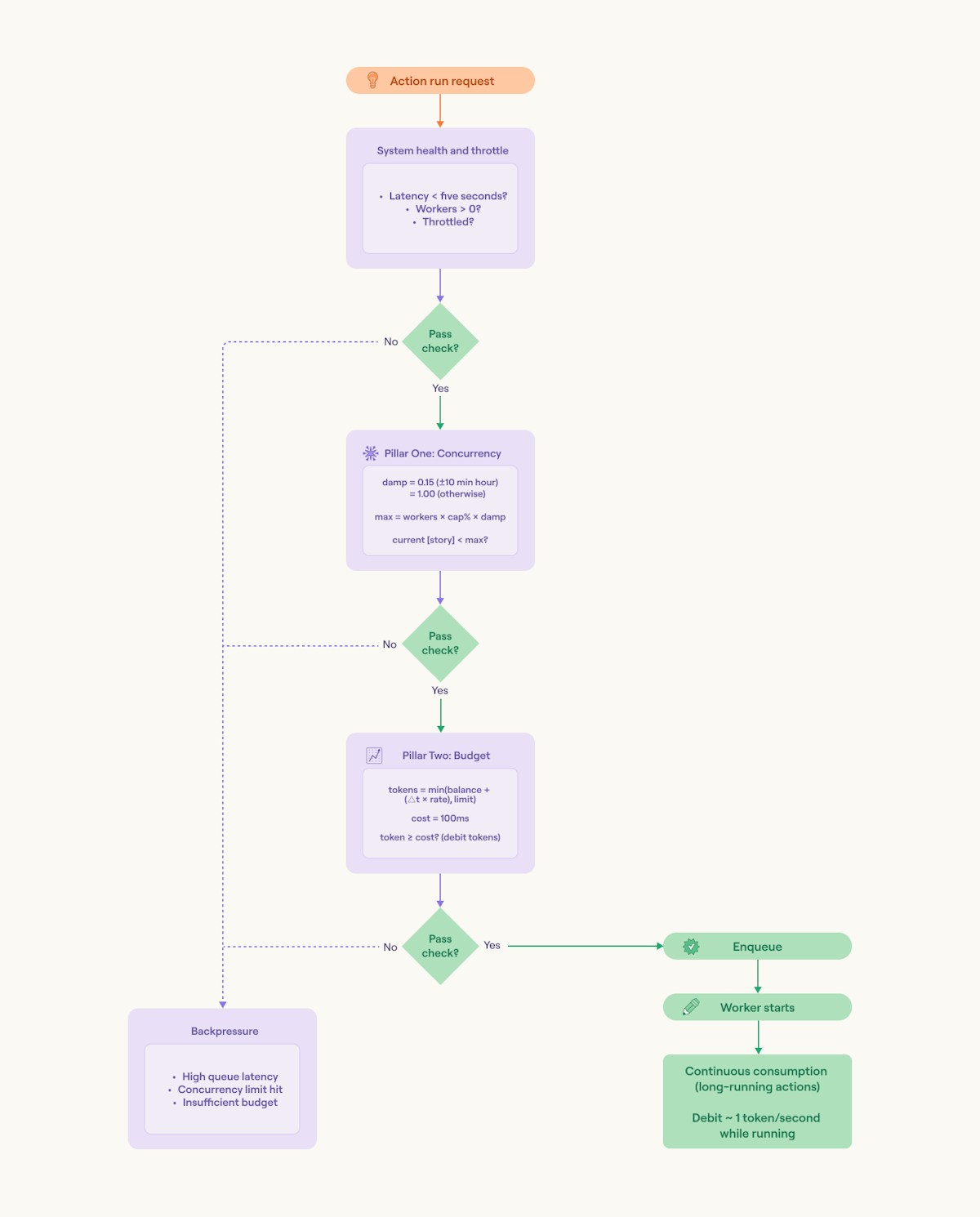
How it works
Pillar 1: Concurrency
The gate
The first pillar focuses on capping a fraction of total workers that can be occupied by action starts at any moment. We compute a live ceiling by multiplying the current Sidekiq worker count by a configured percentage. That percentage is usually static, but in multi-tenant environments we apply a time-based dampener. If the current time is within 10 minutes of the top of the hour, we temporarily reduce the cap, down to 15% of the base value. This desynchronizes the surge of stories that naturally fire on the hour, like scheduled actions, cron-like triggers, batch jobs and prevents a stampede that would overwhelm the queue and spike latency for everyone.
We track live concurrency per story in a Redis set, incremented when an action starts and decremented when it completes. Before enqueuing a new action, we check if the story's current concurrency is below the system-wide cap. If not, we do not enqueue the action run, even if the story has budget.
We don't enqueue new actions until capacity becomes available. This serves to mitigate the risk of a single story monopolizing the fleet, and the cap adapts dynamically as workers scale or become busy. This means heavy stories appropriately slow down, while fast stories remain fast.
Backpressure: knowing when to pause
Ultimately, we don't hide saturation. If the system detects there are not enough open workers available, or the default queue latency exceeds a 5-second threshold, we stop enqueuing and record the decision in telemetry.
If a story is explicitly throttled, using a tenant-scoped percentage flag we can tune per story, we honor it and record that decision to prevent a runaway story from monopolizing the worker fleet.
Pillar 2: Budget
Earning tokens
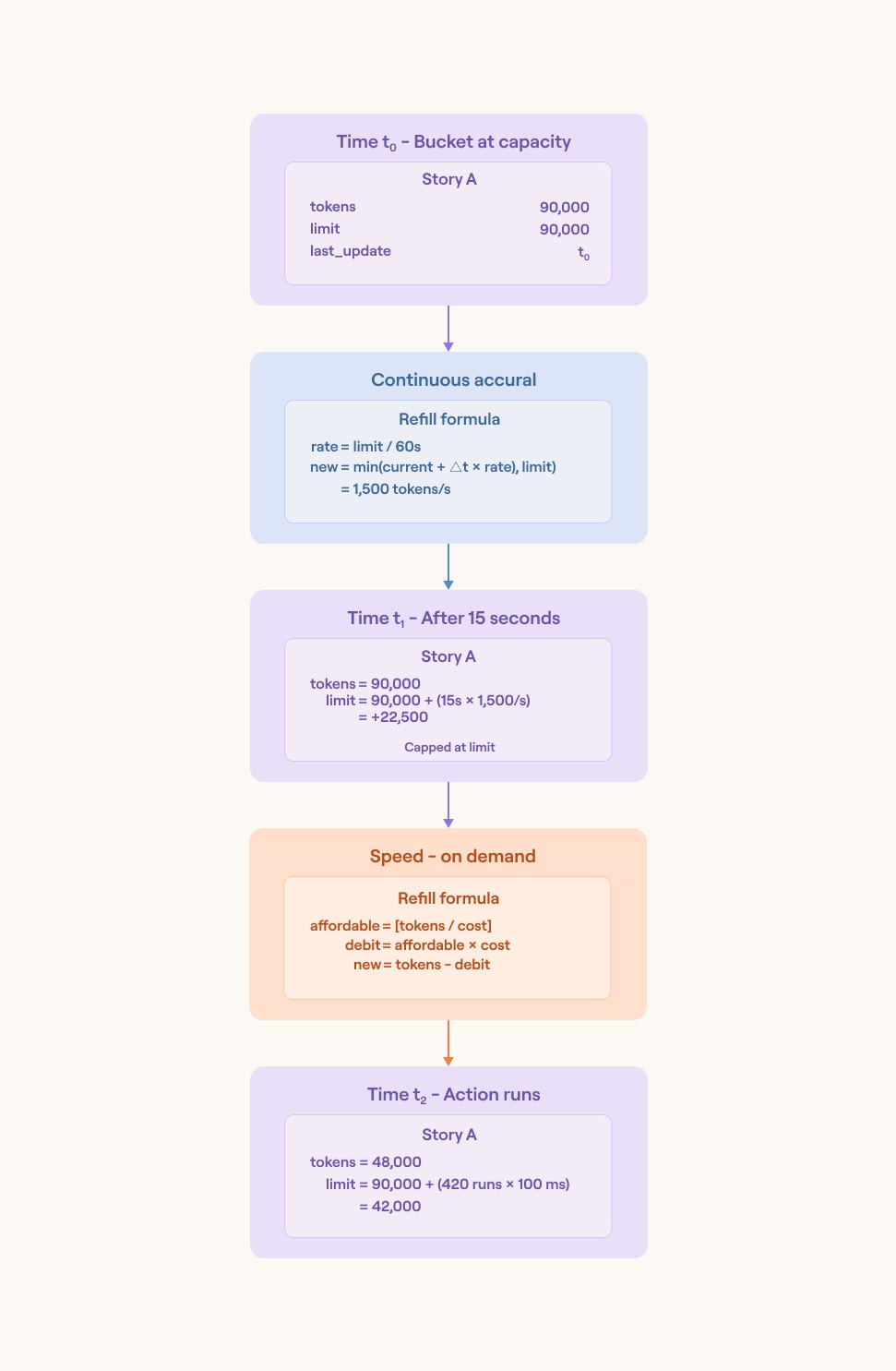
Every story has its own token bucket in Redis. The bucket has a limit that represents how many action runs the story can enqueue per minute.
Tokens accrue proportionally to wall-clock time, not in step-function refills. When the platform checks the budget, it computes elapsed time since the last update, adds tokens at a rate tied to the bucket's limit, clamps to the ceiling, and writes back. This means stories with steady demand get steady budget, and stories that pause will naturally accumulate capacity.
If Redis experiences a transient error during a budget read, the platform fails-open by granting the full configured limit and recording that decision in telemetry. This keeps the platform moving rather than stalling action runs and slowing down customer workflows.
Spending tokens
When an action needs to start, Tines checks the worker budget. The platform estimates the cost based on a baseline duration (100ms for most actions), sees how many runs are affordable given the current balance, clamps the request to that number, and decrements the bucket. If the budget is insufficient, it will return zero affordable runs, the action will not start, and the platform records why in telemetry.
If Redis experiences a transient error during a budget spend, the platform will again fail-open by granting the request and recording that decision in telemetry.
Every spend decision emits a suite of metrics:
tokens available before
runs possible
runs enqueued
tokens consumed
the balance after the fact
This granular accounting makes it straightforward to trace whether a story is bottlenecked by budget, concurrency, or system capacity which helps the platform identify the potential problem.
Here is an example query that we might have in our app:
function spend_budget(story_id, requested_runs, duration=ESTIMATED_ACTION_RUN_DURATION):
tokens_available = refill_tokens(story_id)
runs_possible = floor(tokens_available / ESTIMATED_ACTION_RUN_DURATION)
runs_to_enqueue = min(requested_runs, runs_possible)
tokens_needed = duration * runs_to_enqueue
has_enough_tokens = tokens_needed <= tokens_available
if not has_enough_tokens:
return 0
# Only consume if we're actually enqueuing runs
if runs_to_enqueue > 0:
try:
tokens_after = redis.decrby(token_bucket_key(story_id), tokens_needed)
except RedisTransientError as error:
return requested_runs # fail open
return runs_to_enqueueLong-running consumption: pay as you go
For actions that run longer than the estimated duration, Tines can consume budget continuously in the background; roughly one second's worth of tokens per second of wall clock time. This ensures long-running work costs its fair share over time rather than only at enqueue or dequeue.
When an action is complete, we stop the background consumption.
If Redis is transiently unavailable during a tick, we retry until the action finishes, preserving the pay-as-you-go contract without failing the run.
What we measured
We instrumented the things customers value and us engineers need:
Start and end‑to‑end latencies to capture user‑visible performance.
Capacity context like current concurrency, maximum allowed concurrency, available system workers, and whether tokens are available but workers are unavailable.
Token availability, consumption, and percentage used to understand budget pressure.
A “failed to deliver on promise” metric for cases where a story had available tokens and concurrency headroom, but no system workers available to run. We record it as a first‑class signal that we are not meeting the promise from our system's side and take actions to investigate. It surfaces when fleet scaling or external bottlenecks are the real constraint.
Results
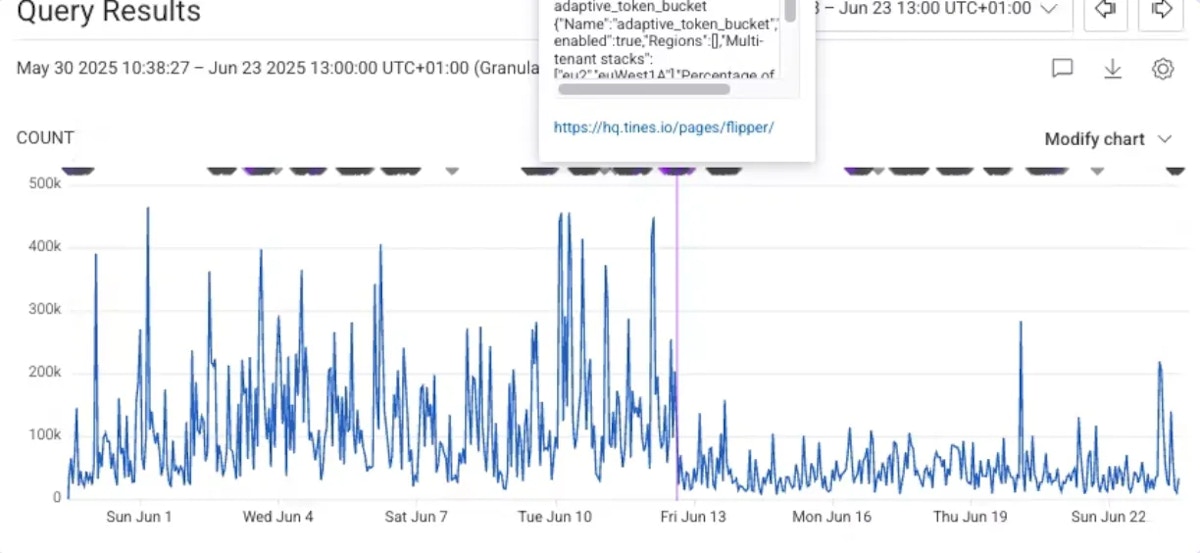
More predictable performance
This chart illustrates our capacity optimization at work. Before the purple line, high-demand periods created queuing. After we rolled out our new implementation on the platform, workflows are scheduled more intelligently - resulting in smoother, more predictable execution across the platform
Evolving our core engine
These continuous investments ensures that we are making the system as predictable and as fair as possible for our customers. Each story gets its share of resources, bounded by explicit contracts that the system honors even under saturation. This enables the platform to continue to scale action runs as our customer base grows.. The continuous token accrual and concurrency gate are algorithmically O(1) per action run so they scale as story count grows.
The Redis-backed accounting and its fail-open semantics mean transient infrastructure issues don't cascade.
We currently run over billion action runs a week in cloud environments. This work allows us to prepare for the next 10x increase as we continually improve our system.
What we learned
Simplicity wins
We resisted the temptation to add per-tenant, per-team, or per-folder limits. Story-level fairness with a global concurrency gate proved sufficient and much more maintainable. Fewer controls to fine tune meant faster iterations to scale with the customer and a clearer mental model when debugging something as critical as action runs so any customer issues are resolved faster.
Budget alone isn't enough
We initially explored implementing a continuously accruing per-story budget, assuming smooth token refills would naturally limit parallelism. It didn't. A story with full budget could still flood the system during refills, creating the exact burst behavior we were trying to prevent.
The concurrency gate, a hard cap on instantaneous worker consumption was needed.
Budget controls cumulative work and concurrency controls instantaneous load. Both are necessary to reduced the frequency of worker monopolization.
What’s next
Our fairness system has solved the problem of resource distribution, and now no single story monopolize capacity.
As we scale further from ~1 billion action runs per week, we're starting to observe database write amplification problems. Each action run generates 5-6 database writes, and PostgreSQL's MVCC amplifies these into heavy physical I/O operations from WAL writes, index updates, and tuple versioning.
We’re currently exploring batch database writes for sequences of idempotent actions and make budgeting story-run-aware to keep serving new story runs.
We're also exploring dedicated queues for I/O-heavy actions, so slow external API calls do not compete with fast compute tasks.
As we scale, our north star remains the same - making sure every customer's workflows run reliably and predictably, no matter how much the platform grows.