

One commonly used feature with Tines is the ability to configure your Actions to run on a schedule (docs). For example, an HTTP Request Action that runs every minute, once a day, or every few hours. Our customers rely heavily on this feature in carrying out their mission-critical workflows.
In this post, we examine how our old job scheduler system worked, a very interesting race condition, and why we replaced our old scheduler with something more reliable to meet our delivery guarantees.
It starts with an incident
On a calm Tuesday evening, one of our customer support engineers surfaced a customer flagged issue - our customer noticed one of their Actions that was supposed to run once a day hadn’t on the given day 😱.
So, we immediately started looking and soon realized this issue impacted more than one customer. We spun up an incident and got all hands on deck to investigate, gather evidence and mitigate the incident as soon as possible.
At the time of the incident, the primary cause wasn’t entirely clear. We found a smoking gun from our logs that indicated a fatal exception, leading to a set of Action runs not getting executed on the next hour mark. Hence, the missed Action run that our customer correctly pointed out. At this time, we knew enough about where the problem originated from and immediately shipped a patch to ensure this same situation didn’t happen again. We followed up with comms to all the customers impacted by this issue.
Even though we shipped a patch, not having a good mental model of the contributing factors didn’t sit right with us. After a thorough deep dive, we compiled a list of things that happened simultaneously for this kind of scenario to present itself.
Deep dive
Before we begin, it might be helpful to gain a bit of context about this part of the system.
We use an open-source Ruby gem called sidekiq-scheduler that takes care of scheduling jobs which are later processed by Sidekiq.
Sidekiq is a popular and reliable gem for processing async jobs in a Ruby/Rails application.
sidekiq-scheduler makes it easy to run jobs on a schedule.
Our customers define the schedule for their Action runs via Tines product UI.
Our system has both static and dynamic jobs.
Static Jobs: These are a finite set of Sidekiq jobs defined via a YAML file. These are primarily internal jobs that run on schedule.
Dynamic Jobs: These jobs represent scheduled Action runs by our customers.
We store the configuration for dynamic jobs as standard cron syntax in our database.
When a new dynamic job is added or updated by our customer, we append the same in Redis as well, so it is available to be queued by sidekiq-scheduler.
As part of the shutdown and start-up events, a few things happen:
When a Sidekiq service shuts down
sidekiq-scheduler clears the schedule (static and dynamic) in Redis.
When a Sidekiq service starts up
sidekiq-scheduler only adds the static schedule in Redis.
In addition, we also have an internal job that ensures all dynamic jobs are also in Redis when a new Sidekiq process boots. The internal job adds the Action runs (dynamic jobs) by clearing the entire schedule first and then re-adding static & dynamic jobs.
Lastly, our setup of sidekiq-scheduler runs an additional Ruby Thread in the background every 5 seconds; let's call it the reconciler. It reconciles static and dynamic jobs to ensure the right jobs are in Redis to be queued on time.
What happened
Around 12:56 PM on this day, a rolling deployment had gone out. Around ~12:59 PM, old processes are shutting down, and new processes are coming up. At 12:59:49 PM, one of the new processes experienced a fatal exception and crashed. At 1:00:01 PM, a new process comes online and registers the schedule in Redis.
During this time, any scheduled Action run that was supposed to run on the hour mark (1:00 PM) was missed. This was because between 12:59:49PM - 1:00:01PM (12 seconds), there was no schedule registered in Redis. Any job registered with a schedule at 1:00:01PM or after will get executed on their next run time.
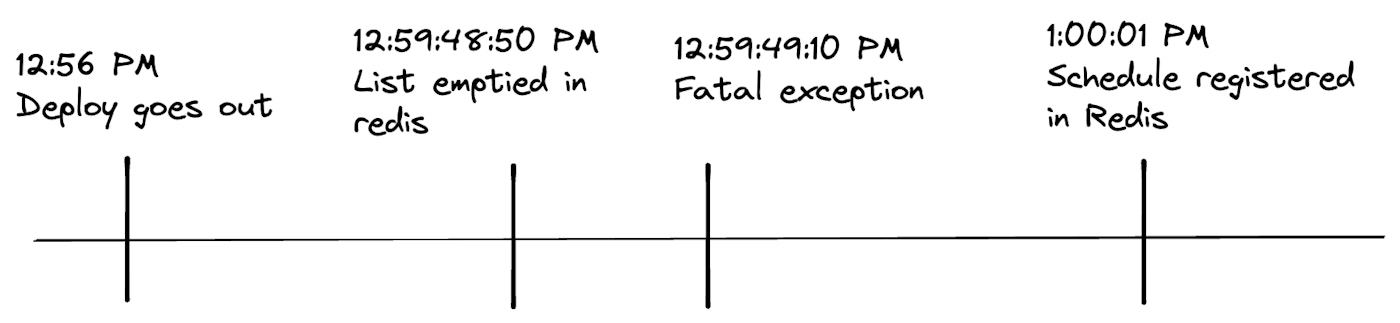
Fatal exception caused by a race condition
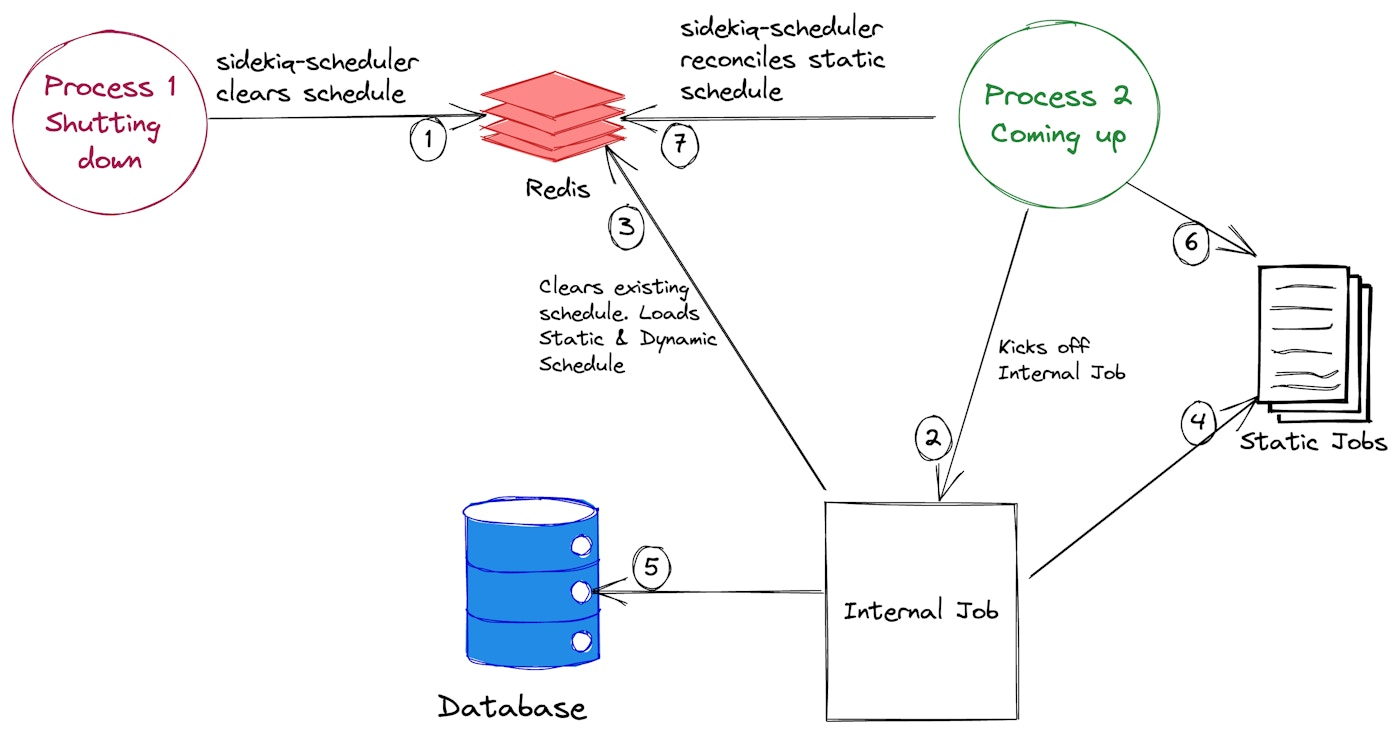
As mentioned above - with each deployment, when a process shuts down, sidekiq-scheduler clears the schedule; next, when a new process starts up, the static schedule is loaded back in Redis by sidekiq-scheduler and the dynamic jobs are loaded by an internal job.
Now, around this time, the reconciler pulled a list of jobs from Redis and tried updating the list with any potential new schedules. But a new process (as part of the deployment) that had just spun up and kicked off the internal job to add back dynamic jobs to Redis (that may have been removed as part of the rolling deployment) by clearing the old list first. The timing of clearing the list in Redis from the internal job and the reconciler thread trying to update the schedule in Redis overlapped, and the reconciler thread crashed hard when it couldn’t correctly reference the list of jobs. At this point, there was no active scheduler instance in the stack, and no scheduled jobs were queued at the hour mark.
It crashed hard because this expression Sidekiq.schedule[schedule_name] returned nil due to the lack of jobs registered in Redis.
A very rough snapshot and a high-level overview of the events that occurred ~12:59 PM.
Had this happened at 1:17 PM, for example, the effects would be much less severe since most of the dynamic jobs run at a 15 min, 30 min, or hourly mark.
This shows a set of contributing factors from completely independent parts of the system resulting in a fatal situation.
Where do we go from here?
We felt good about having a more precise mental model of the incident. Although not so good about the current set of systems. The bi-modality of two unrelated parts of the system mutating a common set of attributes in a central datastore hinted at more future unexpected race conditions.
We also wanted something much easier to grasp and reason about. As we started to think about the evolution of our scheduler system - We considered a few solutions that deal with building a more sophisticated consensus-based system that handles the scheduling and queueing in-house. Ultimately, we settled on something that nicely embraces our values of Simplicity, Speed, and Soundness. Something where we can use our existing tooling and reusable patterns.
New Scheduler
We started by understanding the requirements of the new scheduler system - it is critical that we never miss a scheduled job, and less essential to run the job right on the dot (atomicity). It’s ok if the job run is off by half a second or a second. As a product offering - the lowest denomination we support is per minute Action runs.
Any potential risk of missed Action Runs kept us up at night, so we paused our cycle goals and created a small project comprised of three engineers total (including our Head of Engineering) to see if we could build a prototype and start using it on some of our internal stacks as soon as possible.
The idea is - we continue using sidekiq-scheduler for all static jobs, but we use the new scheduler for all dynamic jobs (Action runs from our customers). We decided to use the Database as the primary source of truth for all schedules and their subsequent runs.
Every minute, we run a Sidekiq job (enqueued by sidekiq-scheduler) that acts as a “fan out” job. It queries the database for any Action Run that is supposed to be executed in the current time window and accordingly queues those jobs to be processed by Sidekiq.
The logic looks something like this:
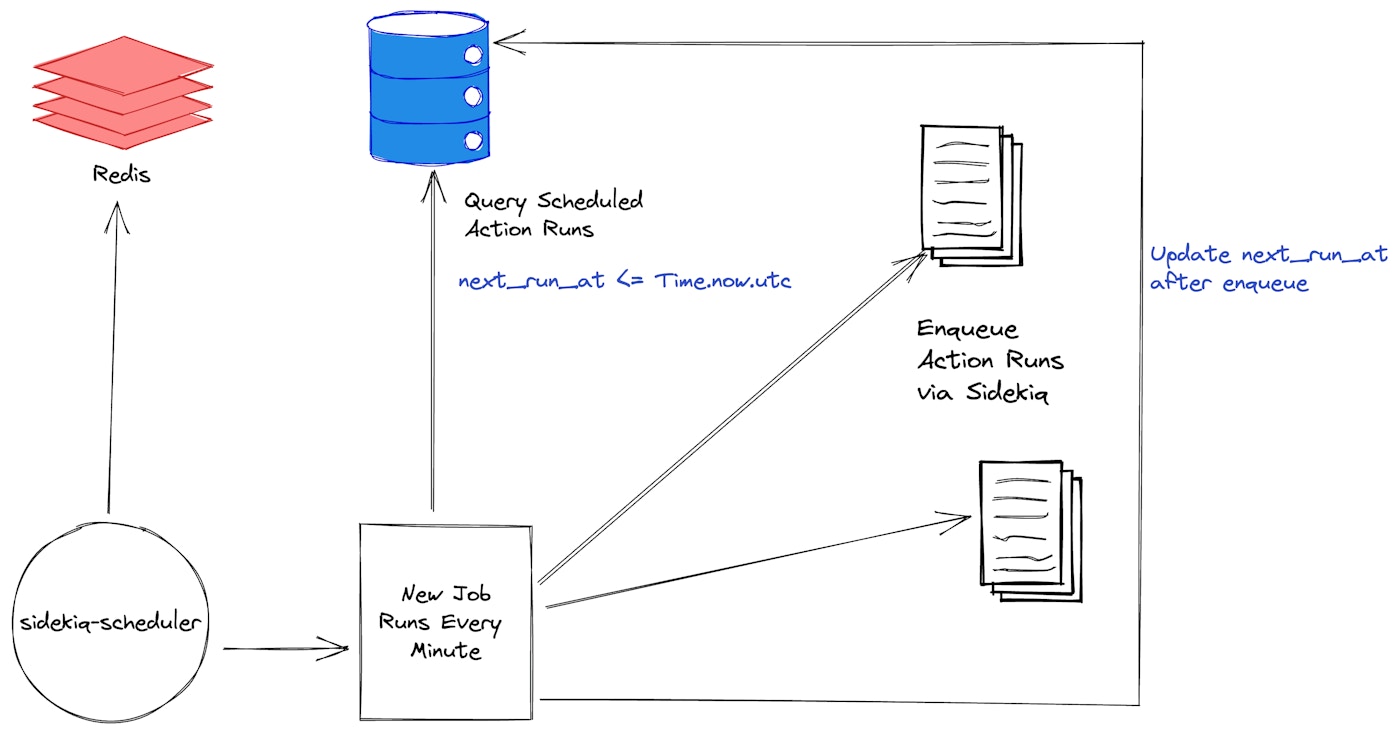
ActionSchedule.where("next_run_at <= ?", Time.now.utc).find_each(&:run)
# ...
def run
return if next_run_at > Time.now.utc
# optimistic concurrency control:
rows_updated =
self
.class
.where(id: id, cron: cron, timezone: timezone, next_run_at: next_run_at)
.update_all(next_run_at: calculate_next_run_at)
enqueue_action_run if rows_updated == 1
end
# ...
def calculate_next_run_at
Fugit::Cron.parse("#{cron} #{timezone}").next_time.to_utc_time
endOne of the nice things about this is - it is idempotent. If something goes off in the static scheduler and we end up enqueuing the fan out job twice, the optimistic concurrency control guarantees (via PostgreSQL) that the same Action Run won’t get enqueued twice. And, no more missed jobs, either.
We were able to come up with the prototype in two days and rolled it out on all internal stacks right away. The system worked much better than our old system. None of our monitoring caught any missed runs; the instrumentation only gave us further confidence as we had before and after data to compare. The following week, we rolled the new scheduler for all customers (Cloud and Self Hosted) and haven’t seen any issues since then.
What is next
Every incident presents an opportunity, and we are happy with the learnings and outcomes from this specific incident. The new scheduler greatly improves the reliability & delivery of our dynamically scheduled jobs.
At Tines, we try to choose existing tooling and reusable patterns wherever possible in solving our engineering challenges. We have a bunch of other efforts ongoing that further increase the reliability of our overall systems, and we plan on sharing more about them with you in the future.